建立数据通路:指令 + 运算=CPU
指令周期
- Fetch(取得指令):从内存里把指令加载到指令寄存器中。
- Decode(指令译码)
- Execute(执行指令)
重复操作这三步,这个循环称为指令周期。
不同的步骤在不同组件内完成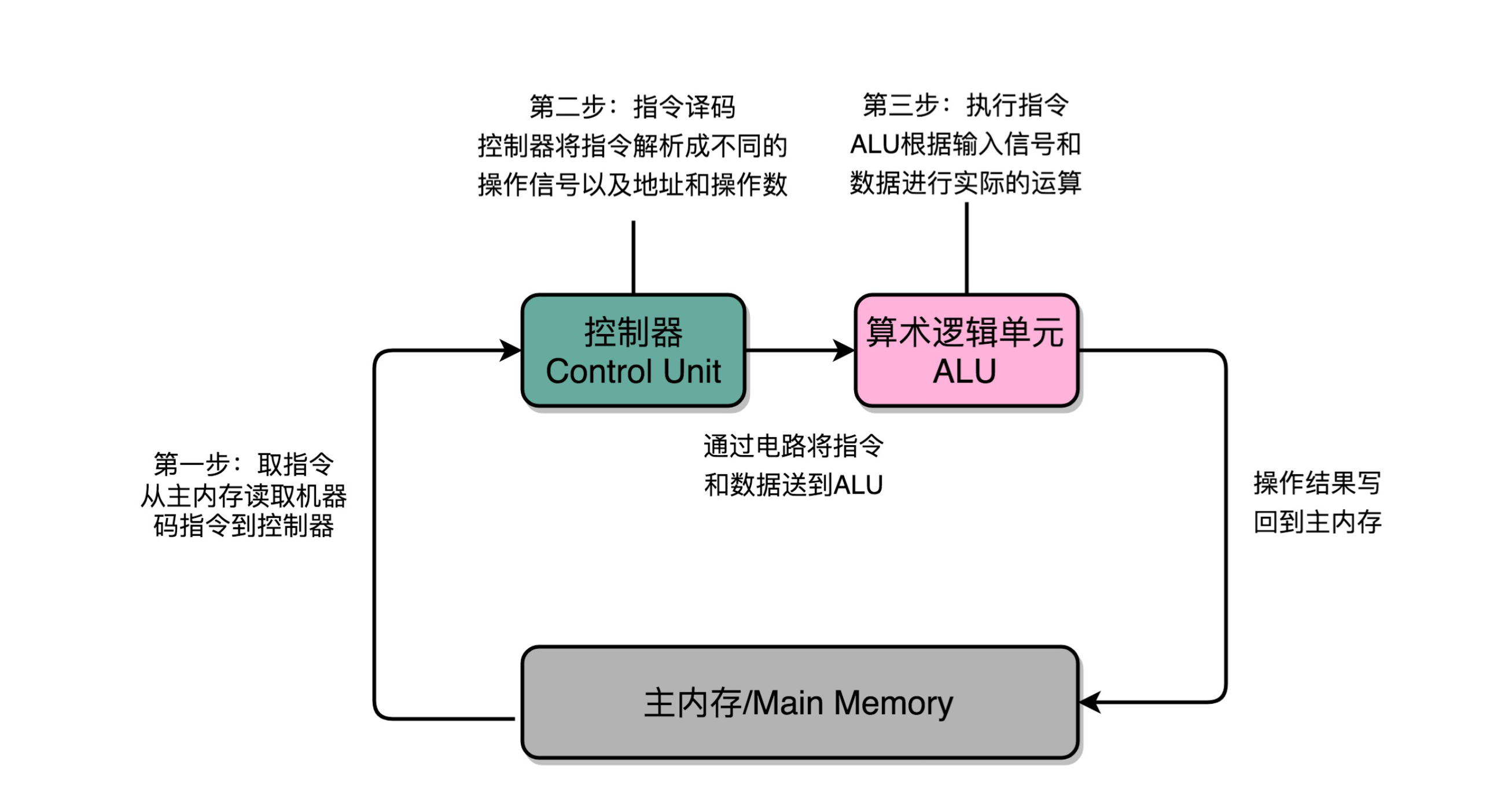
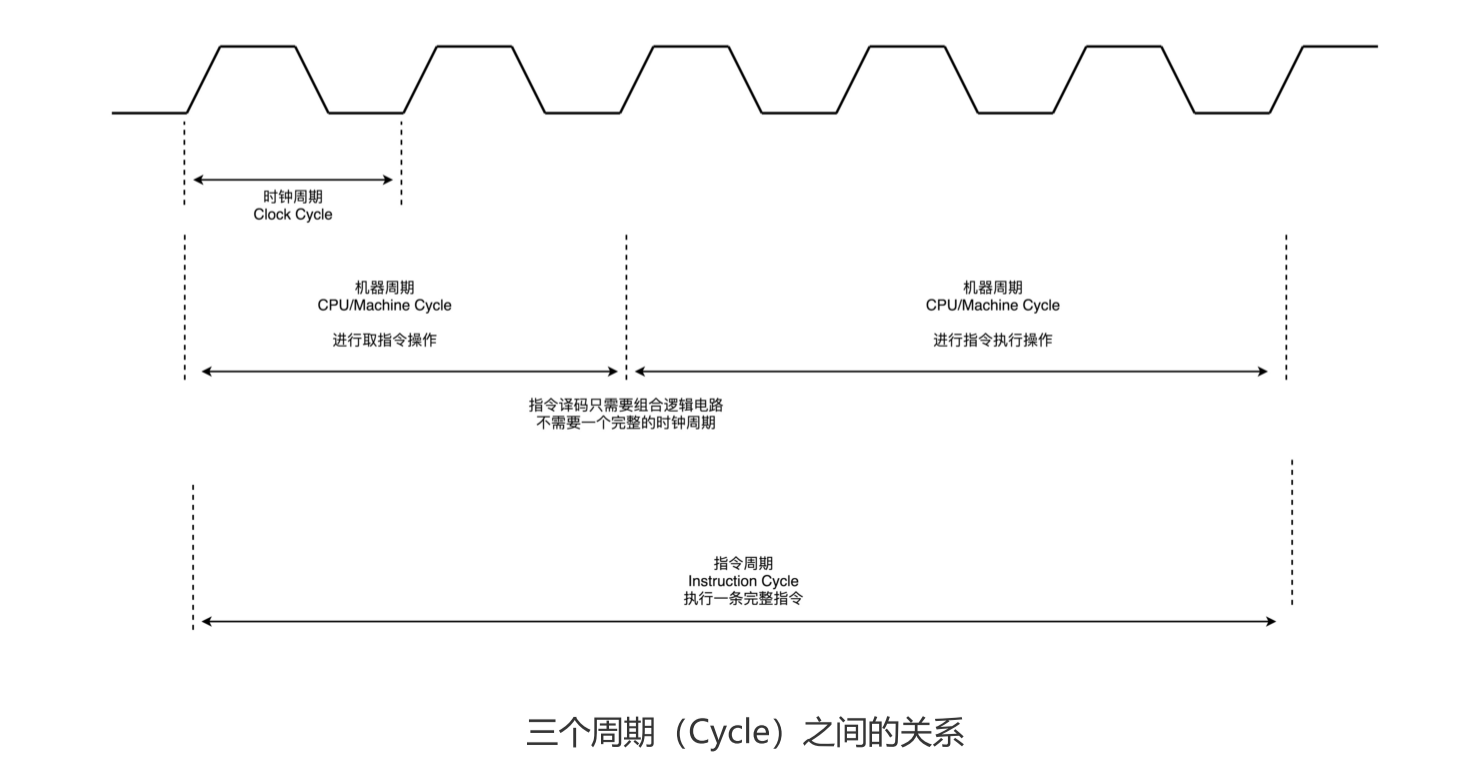
机器周期/CPU周期:从内存里读取一条指令的最短时间。
时钟周期:就是机器的主频,一个 CPU 周期由多个时钟周期组成。
操作元件:组合逻辑元件,ALU,功能是在特定的输入下,生成特定的输出。
存储元件:状态元件,寄存器。
将操作元件,操作原件通过数据总线的方式连接起来,就建立了数据通路了。
控制器:循环执行取址-译码,产生控制信号交给 ALU 处理。电路特别复杂,CPU 如果支持 2000 个指令,意味着控制器输出的信号有 2000 个不同的组合。
CPU 需要的电路
- 根据输入计算出结果的一个电路,ALU
- 能够进行状态读写的电路元件,寄存器
- 按照固定周期,不停实现 PC 寄存器自增的电路
- 译码电路,能够对于拿到的内存地址获取对应的数据或者指令
Q : CPU 好像一个永不停歇的机器,一直在不停地读取下一条指令去运行。那 为什么 CPU 还会有满载运行和 Idle 闲置的状态呢?
A:CPU 还会有满载运行和 Idle 闲置的状态,指的系统层面的状态。即使是 Idle 空闲状态,CPU 也在执行循环指令。
操作系统内核有 idle 进程,优先级最低,仅当其他进程都阻塞时被调度器选中。idle 进程循环执行 HLT 指令,关闭 CPU 大部分功能以降低功耗,收到中断信号时 CPU 恢复正常状态。CPU 在空闲状态就会停止执行,即切断时钟信号,CPU 主频会瞬间降低为 0,功耗也会瞬间降为 0。由于这个空闲状态是十分短暂的,所以你在任务管理器也只会看到 CPU 频率下降,不会看到降为 0。当 CPU 从空闲状态中恢复时,就会接通时钟信号,CPU 频率就会上升。所以你会在任务管理器里面看到 CPU 的频率起伏变化。
实现一个完整的 CPU,除了组合逻辑电路,还需要时序逻辑电路。因为组合逻辑电路只是处理固定输入,得到固定输出,这种电路只能协助我们完成一些计算工作,干不了太复杂的工作。
时序逻辑电路可以解决这几个问题:
- 自动运行问题
时序电路接通之后可以不停地开启和关闭开关,进入一个自动运行的状态。这个使得我们上一讲说的,控制器不停地让 PC 寄存器自增读取下一条指令成为可能。 - 存储问题
通过时序电路实现的触发器,能把计算结果存储在特定的电路里面, 而不是像组合逻辑电路那样,一旦输入有任何改变,对应的输出也会改变。 - 时序协调问题
无论是程序实现的软件指令,还是到硬件层面,各种指令的操作都有先后的顺序要求。时序电路使得不同的事件按照时间顺序发生。
解决自动运行问题
实现时序逻辑电路的第一步就需要一个时钟。CPU 的主频是一个晶振来实现的,晶振生成的电路信号就是我们的时钟信号。
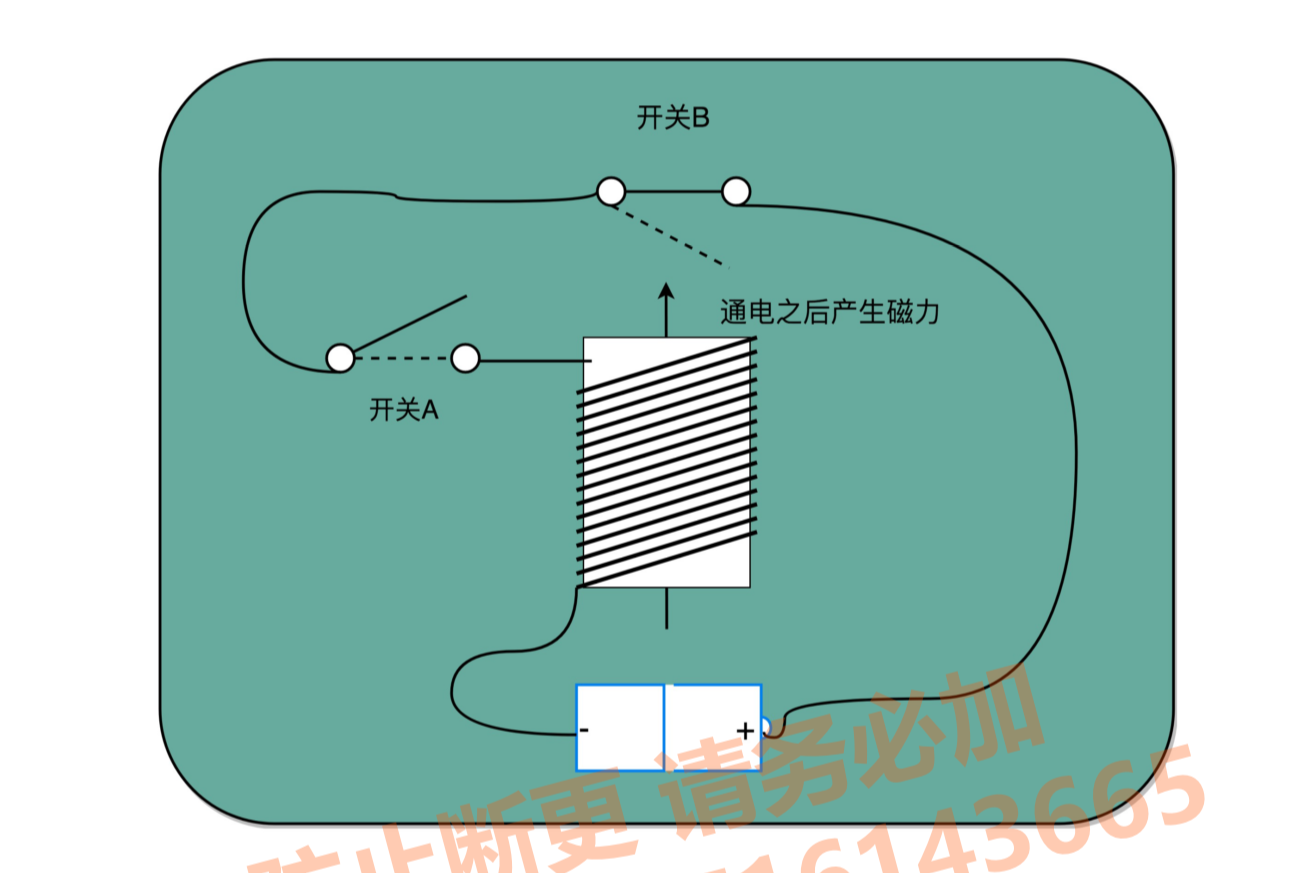
实现如图所示,我们在原先一般只放一个开关的信号输入端,放上了两个开 关。一个开关 A,一开始是断开的,由我们手工控制;另外一个开关 B,一开始是合上的,
磁性线圈对准一开始就合上的开关 B。
于是,一旦我们合上开关 A,磁性线圈就会通电,产生磁性,开关 B 就会从合上变成断 开。一旦这个开关断开了,电路就中断了,磁性线圈就失去了磁性。于是,开关 B 又会弹 回到合上的状态。这样一来,电路接通,线圈又有了磁性。我们的电路就会来回不断地在开
启、关闭这两个状态中切换。
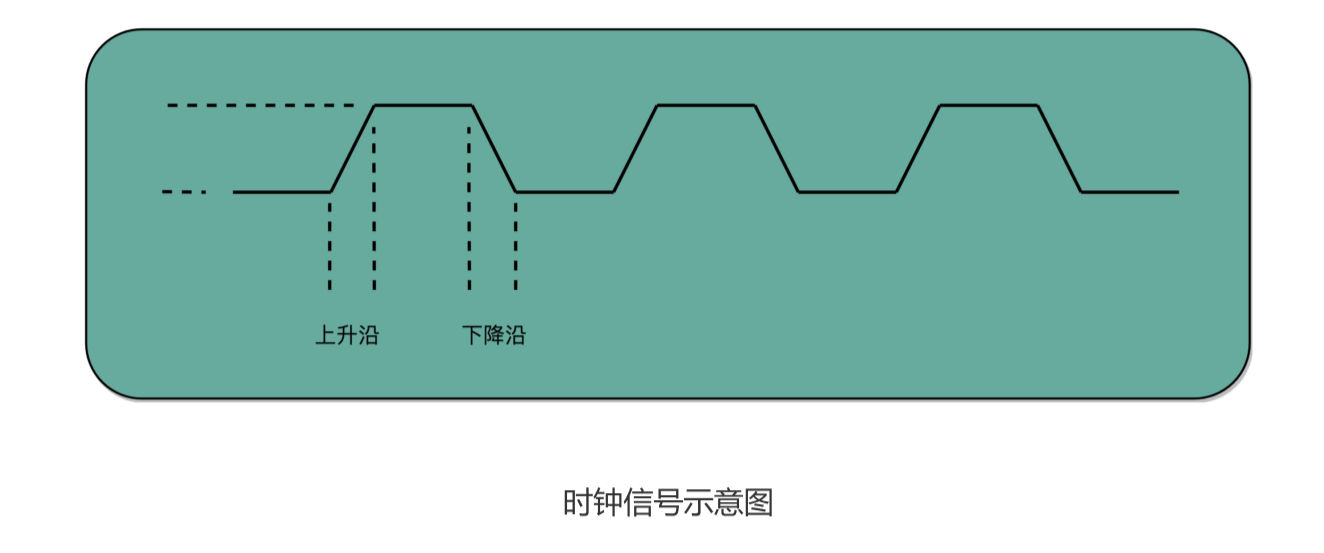
这个不断切换的过程,对于下游电路来说,就是不断地产生新的 0 和 1 这样的信号。如果 你在下游的电路上接上一个灯泡,就会发现这个灯泡在亮和暗之间不停切换。这个按照固定的周期不断在 0 和 1 之间切换的信号,就是我们的时钟信号。
一般这样产生的时钟信号,就像你在各种教科书图例中看到的一样,是一个振荡产生的 0、1 信号。
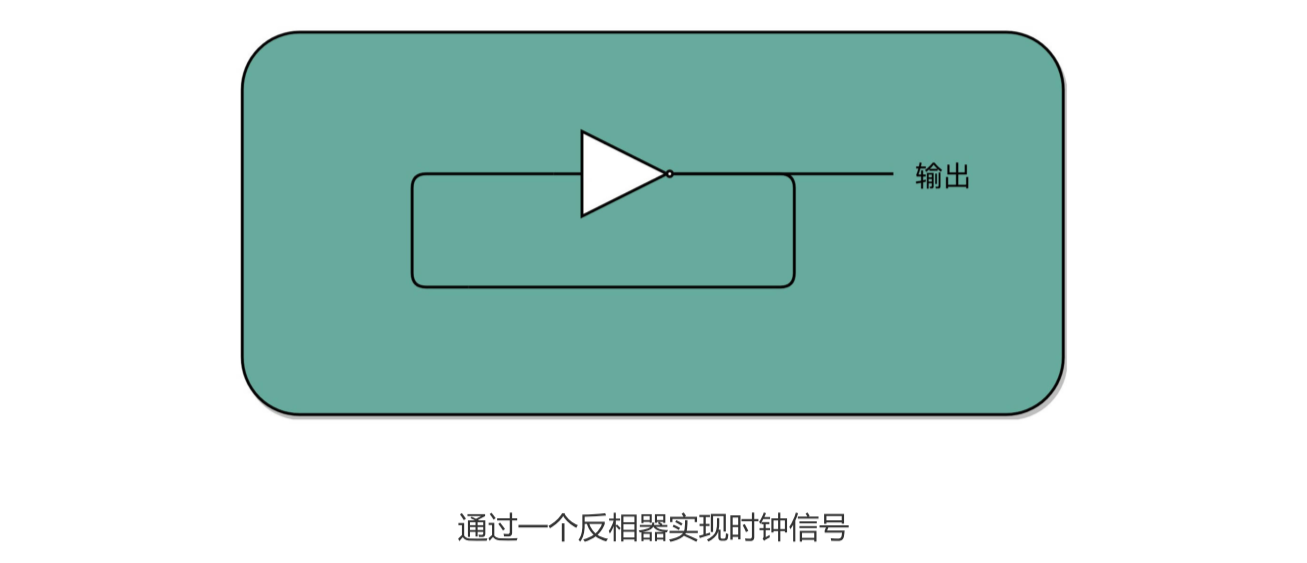
这种电路,其实就相当于把电路的输出信号作为输入信号,再回到当前电路。这样的电路构 造方式呢,我们叫作反馈电路(Feedback Circuit)。
上面这个反馈电路一般可以用下面这个示意图来表 示,其实就是一个输出结果接回输入的反相器(Inverter),也就是我们之前讲过的非门。
解决存储问题
有了时钟信号,我们的系统里就有了一个像“自动门”一样的开关。利用这个开关和相同的 反馈电路,我们就可以构造出一个有“记忆”功能的电路。
我们先来看下面这个 RS 触发器电路。这个电路由两个或非门电路组成。我在图里面,把它 标成了 A 和 B。
或非门真值表:
|NOR|0| 1|
| —- | —- | —- |
|0|1|0|
|1|0|0|
- 在这个电路一开始,输入开关都是关闭的,所以或非门(NOR)A 的输入是 0 和 0。对 应到我列的这个真值表,输出就是 1。而或非门 B 的输入是 0 和 A 的输出 1,对应输出 就是 0。B 的输出 0 反馈到 A,和之前的输入没有变化,A 的输出仍然是 1。而整个电 路的输出 Q,也就是 0。
- 当我们把 A 前面的开关 R 合上的时候,A 的输入变成了 1 和 0,输出就变成了 0,对应 B 的输入变成 0 和 0,输出就变成了 1。B 的输出 1 反馈给到了 A,A 的输入变成了 1 和 1,输出仍然是 0。所以把 A 的开关合上之后,电路仍然是稳定的,不会像晶振那样 振荡,但是整个电路的输出 Q 变成了 1。
- 这个时候,如果我们再把 A 前面的开关 R 打开,A 的输入变成和 1 和 0,输出还是 0,对应的 B 的输入没有变化,输出也还是 1。B 的输出 1 反馈给到了 A,A 的输入变成了 1 和 0,输出仍然是 0。这个时候,电路仍然稳定。开关 R 和 S 的状态和上面的第一步是一样的,但是最终的输出 Q 仍然是 1,和第 1 步里 Q 状态是相反的。我们的输入和刚才第二步的开关状态不一样,但是输出结果仍然保留在了第 2 步时的输出没有发生变 化。
- 这个时候,只有我们再去关闭下面的开关 S,才可以看到,这个时候,B 有一个输入必然是 1,所以 B 的输出必然是 0,也就是电路的最终输出 Q 必然是 0。
这样一个电路,我们称之为触发器(Flip-Flop)。接通开关 R,输出变为 1,即使断开开 关,输出还是 1 不变。接通开关 S,输出变为 0,即使断开开关,输出也还是 0。也就是, 当两个开关都断开的时候,最终的输出结果,取决于之前动作的输出结果,这个也就是我们说的记忆功能。
面向流水线的指令设计
单指令周期处理器
一条 CPU 指令的执行,有三步:取得指令,译码,执行。需要一个时钟周期。自然设计指令时,我们也希望一整条指令能在一个时钟周期内完成。这就是单指令周期处理器。
不过,时钟周期是固定的,但是指令的电路复杂程度是不同的,所以实际一条指令执行的时间是不同的。从前面的学习中也知道,随着门电路层数的增加,门延迟的存在,计算复杂的指令需要的时间更长。
不同指令的执行时间不同,但是我们需要让所有指令都在一个时钟周期内完成,那就只好把执行时间最长的那个指令和时钟周期设成一样。
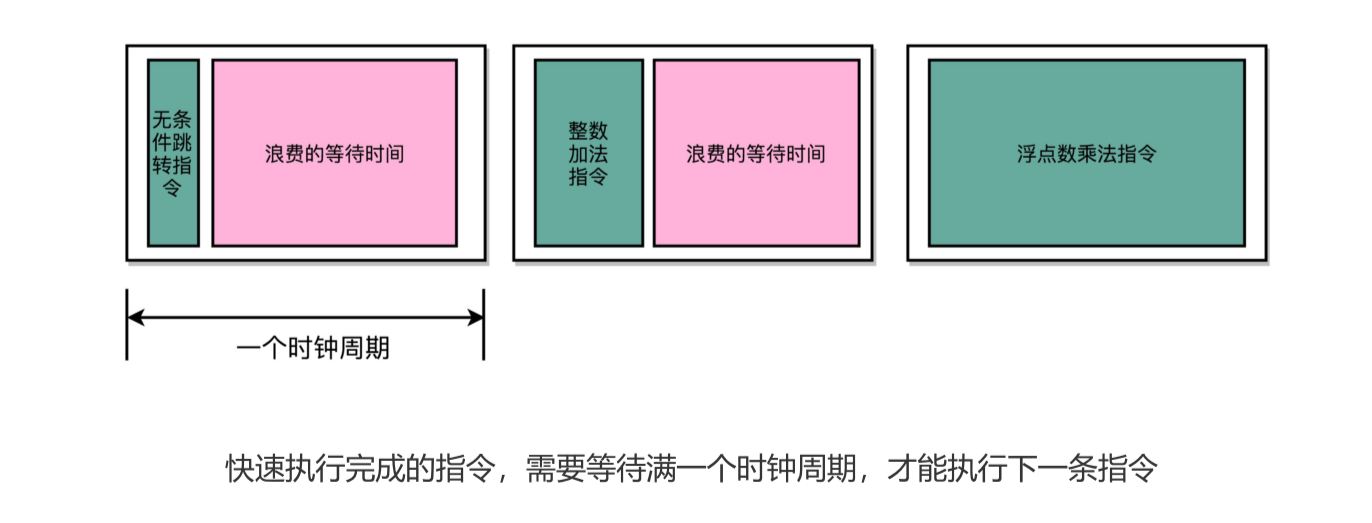
所以,在单指令周期处理器里面,无论是执行一条用不到 ALU 的无条件跳转指令,还是一条计算起来电路特别复杂的浮点数乘法运算,我们都等要等满一个时钟周期。这样时钟频率就无法提高,因为太高了,有些复杂指令无法在一个时钟周期内运行完。
到这可能就有人发问了,之前不是说一个 CPU 时钟周期,可以认为是完成一条简单指令的时间。为什么单指令周期处理器上,却成了执行一条最复杂的指令的时间?
这是因为,无论是 PC 上使用的 Intel CPU,还是手机上使用的 ARM CPU,都不是单指令周期处理器,而是采用了一种叫作指令流水线(Instruction Pipeline)的技术。
流水线设计
CPU 执行指令的过程和我们做饭一样,我们不会等米饭蒸好再洗菜,不会等肉腌好再切菜,而是蒸饭时,可以洗菜,腌肉时可以切菜。
CPU 的指令执行过程,其实也是由各个电路模块组成的。我们在取指令的时候,需要一个译码器把数据从内存里面取出来,写入到寄存器中;在指令译码的时候,我们需要另外一个译码器,把指令解析成对应的控制信号、内存地址和数据;到了指令执行的时候,我们需要的则是一个完成计算工作的 ALU。
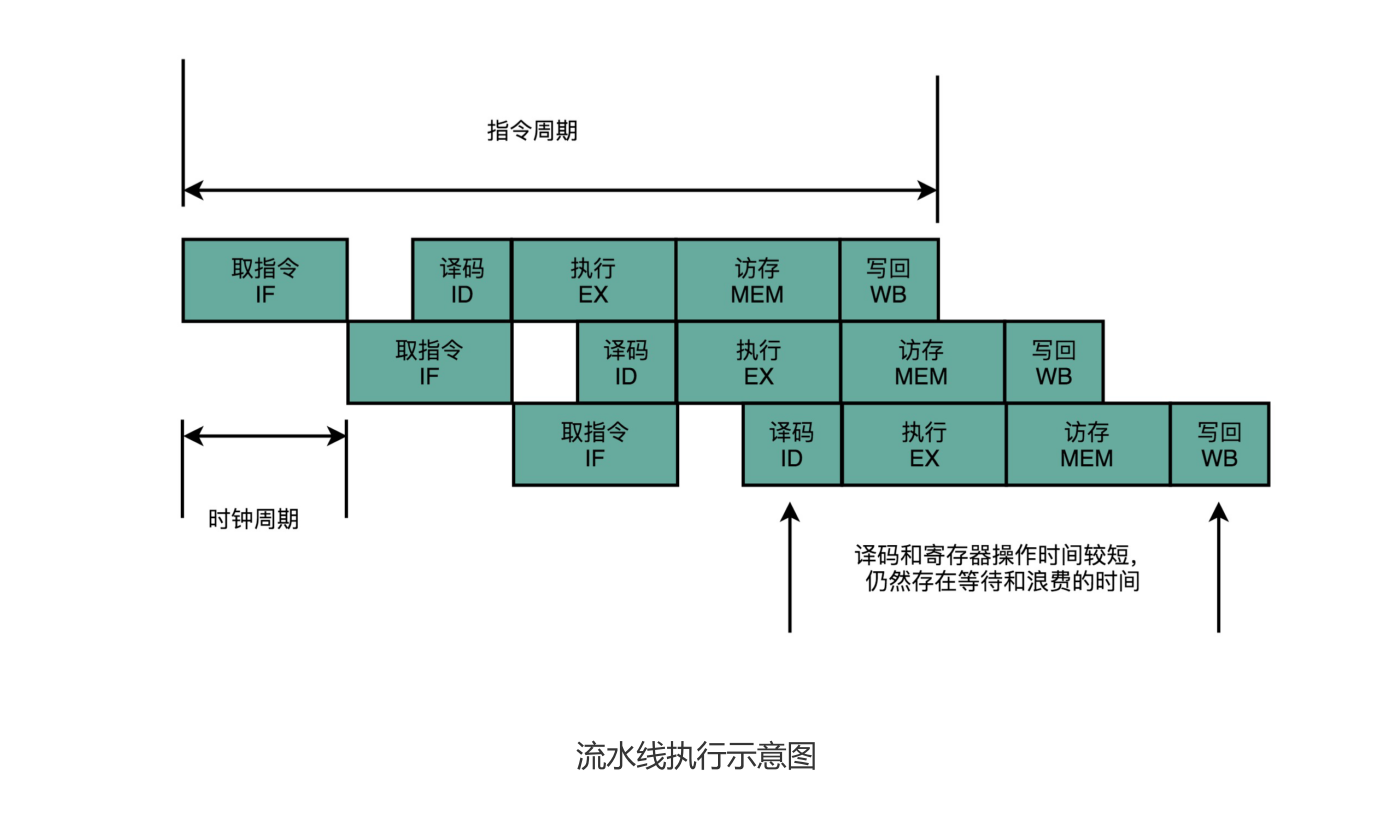
这样一来,我们就不用把时钟周期设置成整条指令执行的时间,而是拆分成完成这样的一个一个小步骤需要的时间。同时,每一个阶段的电路在完成对应的任务之后,也不需要等待整个指令执行完成,而是可以直接执行下一条指令的对应阶段。
如果我们把一个指令拆分成“取指令 - 指令译码 - 执行指令”这样三个部分,那这就是一个三级的流水线。如果我们进一步把“执行指令”拆分成“ALU 计算(指令执行)- 内存访问 - 数据写回”,那么它就会变成一个五级的流水线。
五级的流水线,就表示我们在同一个时钟周期里面,同时运行五条指令的不同阶段。这个时候,虽然执行一条指令的时钟周期变成了 5,但是我们可以把 CPU 的主频提得更高了。我们不需要确保最复杂的那条指令在时钟周期里面执行完成,而只要保障一个最复杂的流水线级的操作,在一个时钟周期内完成就好了。
如果某一个操作步骤的时间太长,我们就可以考虑把这个步骤,拆分成更多的步骤,让所有步骤需要执行的时间尽量都差不多长。
既然流水线可以增加我们的吞吐率,你可能要问了,为什么我们不把流水线级数做得更深 呢?为什么不做成 20 级,乃至 40 级呢?这个其实有很多原因,我在之后几讲里面会详细讲解。这里,我先讲一个最基本的原因,就是增加流水线深度,其实是有性能成本的。
我们用来同步时钟周期的,不再是指令级别的,而是流水线阶段级别的。每一级流水线对应 的输出,都要放到流水线寄存器(Pipeline Register)里面,然后在下一个时钟周期,交给下一个流水线级去处理。所以,每增加一级的流水线,就要多一级写入到流水线寄存器的操作。虽然流水线寄存器非常快,比如只有 20 皮秒(ps,10−12 秒)。
但是,如果我们不断加深流水线,这些操作占整个指令的执行时间的比例就会不断增加。最后,我们的性能瓶颈就会出现在这些 overhead 上。如果我们指令的执行有 3 纳秒,也就 是 3000 皮秒。我们需要 20 级的流水线,那流水线寄存器的写入就需要花费 400 皮秒,占了超过 10%。如果我们需要 50 级流水线,就要多花费 1 纳秒在流水线寄存器上,占到 25%。这也就意味着,单纯地增加流水线级数,不仅不能提升性能,反而会有更多的 overhead 的开销。所以,设计合理的流水线级数也是现代 CPU 中非常重要的一点。
FPGA/ASIC/TPU
FPGA
CPU 是由简单的门电路搭积木一样搭建出来的,那一个 CPU 里有多少个晶体管这样的电路开关呢?一个四核 i7 的 Intel CPU,有 20 亿个晶体管。那么问题来了,我们要设计一个 CPU,就要想办法连接这 20 亿个晶体管。
连接一次已经很难了,我们还要根据问题重新调整连接。设计更简单的特定功能的芯片,少说要几个月。而设计一个 CPU 往往以年计。在这个过程中,硬件工程师要设计、验证各种各样的方案,可能会遇到各种 BUG。如果每验证一个方案都要生产一块芯片,这代价太高了。
我们有没有什么办法,不用单独制造一块专门的芯片来验证 硬件设计呢?能不能设计一个硬件,通过不同的程序代码,来操作这个硬件之前的电路连线,通过“编程”让这个硬件 变成我们设计的电路连线的芯片呢?
这个,就是我们接下来要说的 FPGA,也就是现场可编程门阵列(Field-Programmable Gate Array)。
- P 代表 Programmable,也就是说这 是一个可以通过编程来控制的硬件。
- G 代表 Gate,它就代表芯片里面的门电路。我们能够去进行编程组合的就是这样一个一个门电路。
- A 代表的 Array,叫作阵列,说的是在一块 FPGA 上,密密麻麻列了大量 Gate 这样的门电路。
- F,不太容易理解。它其实是说,一块 FPGA 这样的板子,可以进行在“现场”多次地进行编程。它不像 PAL(Programmable Array Logic,可编程阵列逻辑)这样更古老的硬件设备,只能“编程”一次,把预先写好的程序一次性烧录到硬件里面,之后就不能再修改了。
我们之前说过,CPU 其实就是通过晶体管,来实现各 种组合逻辑或者时序逻辑。那么,我们怎么去“编程”连接这些线路呢?
FPGA 的解决方案分三步:
第一,用存储换功能实现组合逻辑。在实现 CPU 的功能的时候,我们需要完成各种各样的电路逻辑。在 FPGA 里,这 些基本的电路逻辑,不是采用布线连接的方式进行的,而是 预先根据我们在软件里面设计的逻辑电路,算出对应的真值表,然后直接存到一个叫作 LUT(Look-Up Table,查找 表)的电路里面。这个 LUT 呢,其实就是一块存储空间,里面存储了“特定的输入信号下,对应输出 0 还是 1”。
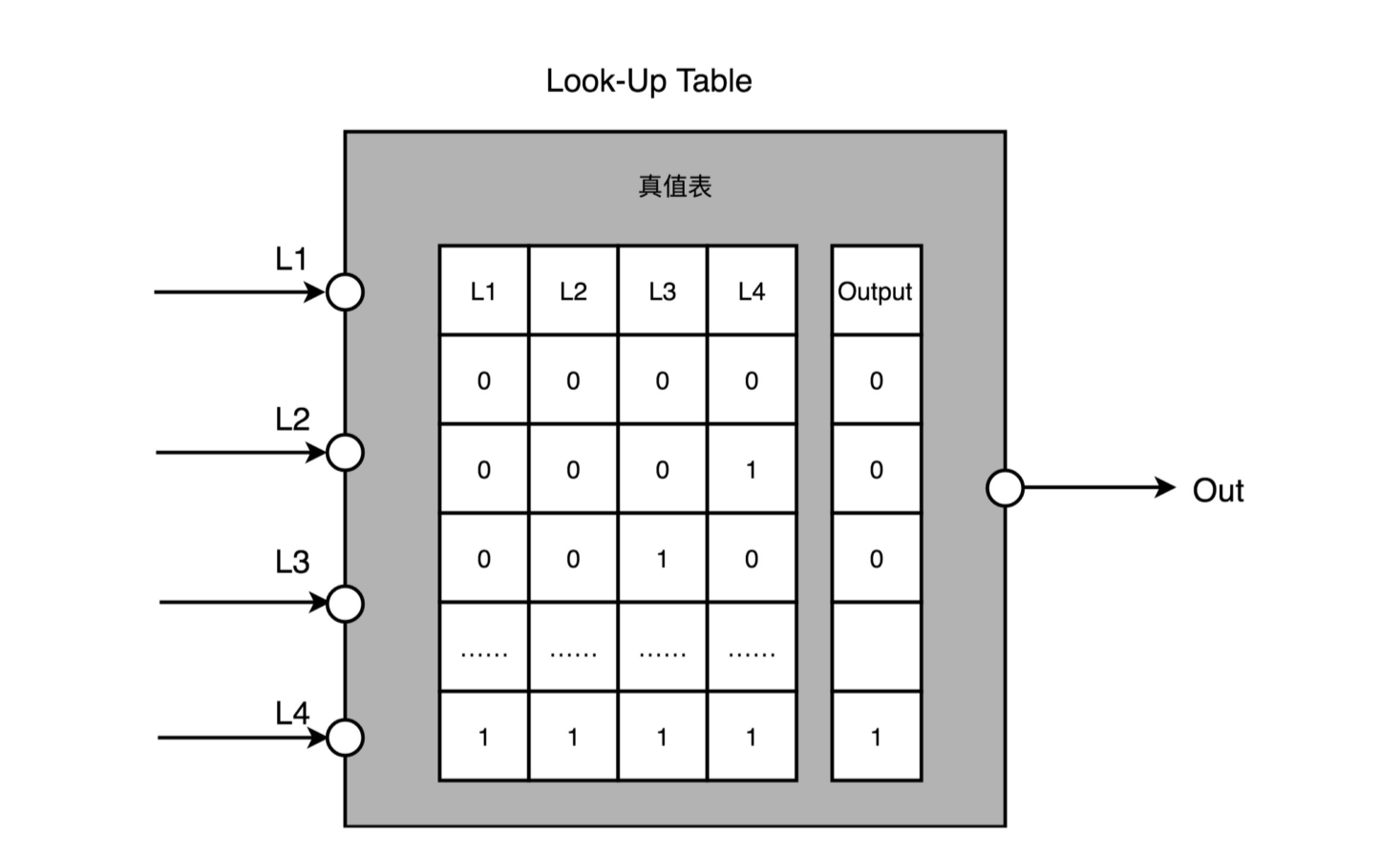
第二,对于需要实现的时序逻辑电路,我们可以在 FPGA 里面直接放上 D 触发器,作为寄存器。这个和 CPU 里的触发器没有什么本质不同。不过,我们会把很多个 LUT 的电路和寄存器组合在一起,变成一个叫作逻辑簇(Logic Cluster)的东西。在 FPGA 里,这样组合了多个 LUT 和寄 存器的设备,也被叫做 CLB Configurable Logic Block,可配置逻辑块)。
可以把 CLB 想象成函数或者 API,设计更复杂的功能,不用重新造轮子,只需要调用函数或者 API 即可。设计芯片也是一样,不用再从门电路开始搭建,可以通过 CLB 组合搭建。
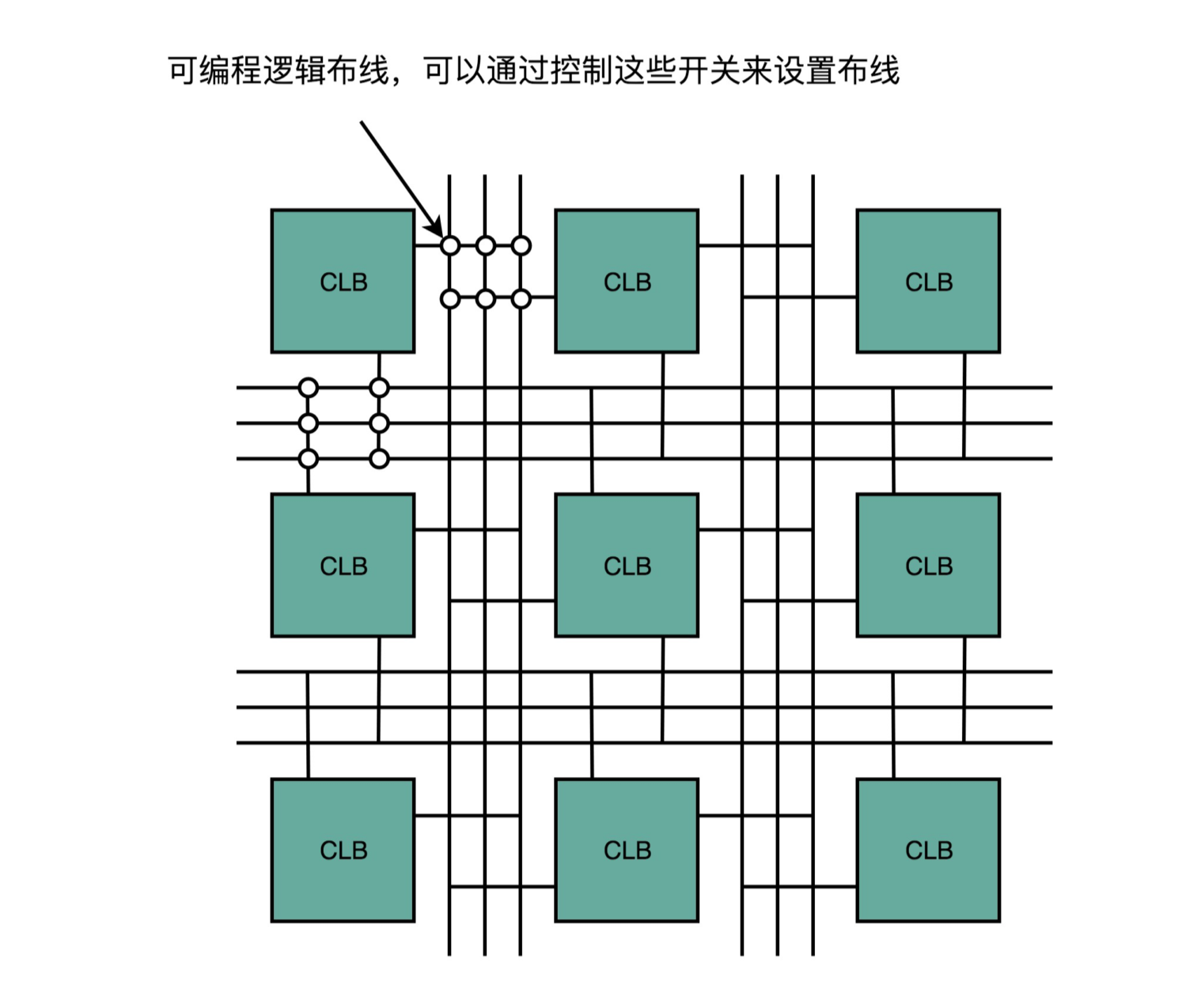
第三,FPGA 是通过可编程逻辑布线,来连接各个不同的 CLB,最终实现我们想要实现的芯片功能。这个可编程逻辑布线,你可以把它当成我们的铁路网。整个铁路系统已经铺 好了,但是整个铁路网里面,设计了很多个道岔。我们可以 通过控制道岔,来确定不同的列车线路。在可编程逻辑布线 里面,“编程”在做的,就是拨动像道岔一样的各个电路开 关,最终实现不同 CLB 之间的连接,完成我们想要的芯片
功能。
ASIC
除了 CPU,GPU 以及 FPGA,我们还需要用到很多其他芯片,比如除了音视频的芯片,或者专门用来挖矿的芯片。尽管 CPU 也能实现这些功能,但是有点大炮打蚊子的感觉。
于是针对一些特殊场景,单独设计一个芯片,我们称这些芯片为 ASIC(Application-Specific Integrated Circuit),专用集成电路。设计精简,制造成本低。
其实我们的 FPGA 也能做 ASIC 的事情,每次对 FPGA 进行编程,就是把 FPGA 电路编程了一个 ASIC。但是如果全用 FPGA,同样会浪费。因为每一个 LUT 电路,都可以实现与门以及或门,这比单纯连死的与门或者或门,用到的晶体管数量要多的多。自然功耗也要大得多,单片 FPGA 的生产制造成本也比 ASIC 要高。
| FPAG | ASIC | |
|---|---|---|
| 一次性成本 | 极低,约等于 0 | 高 |
| 量产成本 | 高 | 低 |
| 延迟 | 低 | 低 |
| 开发周期 | 短 | 长 |
| 市场风险 | 低 | 高 |
| 开发环境 | 设置 FPGA 需要硬件知识,编程和配置门槛很高 | 需要底层硬件变成,开发难度很高 |
TPU
TPU(Tensor Processing Unit)张量处理器;