系统初始化
x86 架构概述
CPU(Central Processing Unit):中央处理器,计算机所有设备都围绕它展开工作。
- 运算单元:只管算,例如做加法、做位移等等。但是,它不知道应该算哪些数据,运算结果应该放在哪里。
- 数据单元:运算单元计算的数据如果每次都要经过总线,到内存里面现拿,这样就太慢了,所以就有了数据单元。数据单元包括 CPU 内部的缓存和寄存器组,空间很小,但是速度飞快,可以暂时存放数据和运算结果。
- 控制单元:有了放数据的地方,也有了算的地方,还需要有个指挥到底做什么运算的地方,这就是控制单元。控制单元是一个统一的指挥中心,它可以获得下一条指令,然后执行这条指令。这个指令会指导运算单元取出数据单元中的某几个数据,计算出个结果,然后放在数据单元的某个地方。
内存(Memory):CPU 本身不能保存大量数据,许多复杂的计算需要将中间结果保存下来就必须用到内存。
总线(Bus):CPU 和其他设备连接,就靠总线,其实就是主板上密密麻麻的集成电路,这些东西组成了 CPU 和其他设备的高速通道。
- 地址总线:传输地址数据(我想拿内存中哪个位置的数据)
- 数据总线:传输真正的数据
总线就像 CPU 和内存之间的高速公路,总线多少位就类似高速公路多少个车道,但两种总线的位数意义不同。
地址总线的位数决定了访问地址范围有多广,数据总线位数决定了一次能拿多少数据进来。那么 CPU 中总线的位数有没有标准呢?如果没有标准,那操作系统作为软件就很难办了,因为软件层没办法实现通用的运算逻辑。早期每家公司的 CPU 架构都不同,后来历史将 x86 平台推到了开放,统一,兼容的位置。
8086 架构图
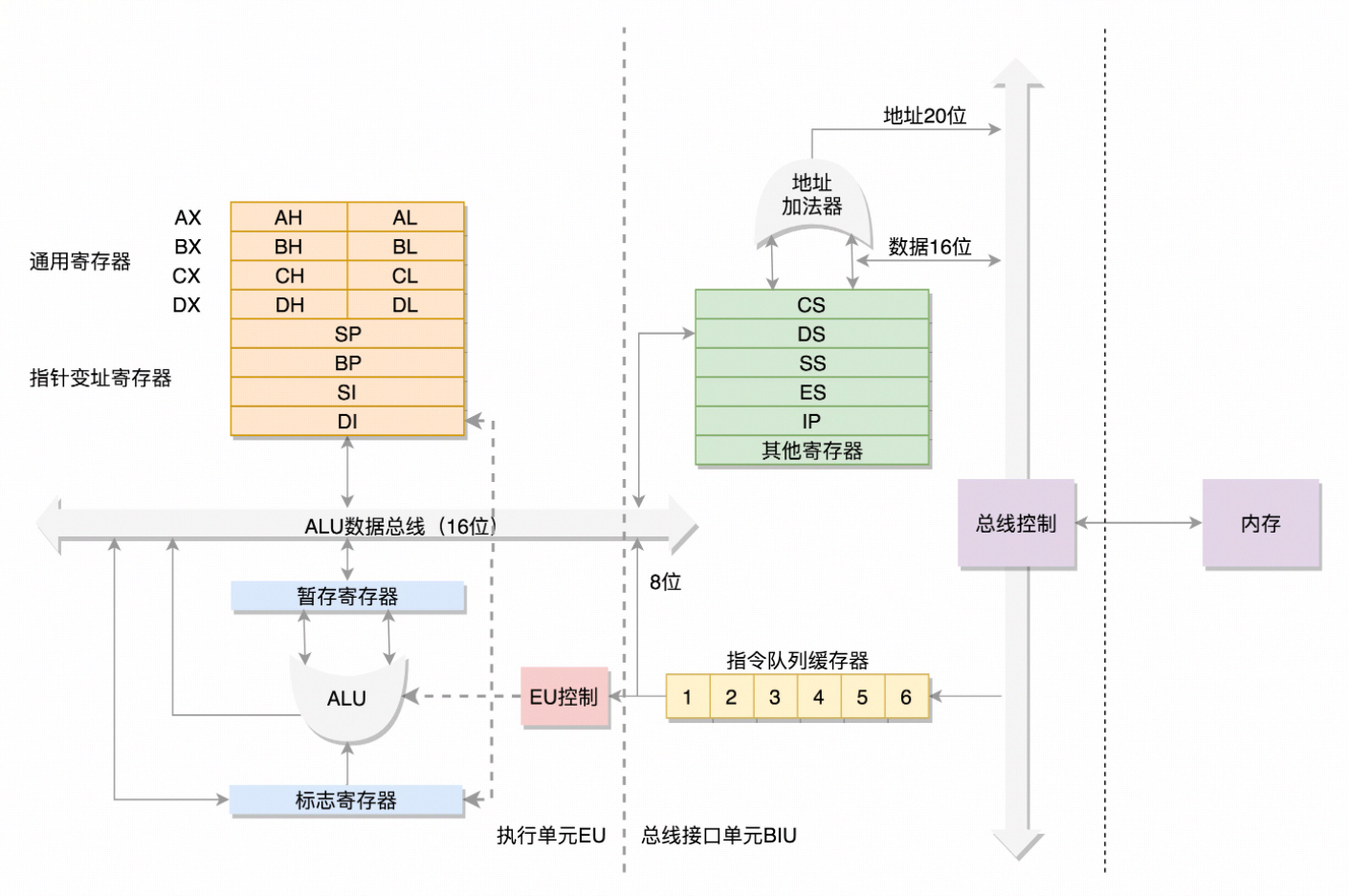
数据单元: 8086 处理器内部共有 8 个 16 位的通用寄存器,分别是 数据寄存器(AX、BX、CX、DX)、指针寄存器(SP、BP)、变址寄存器(SI、DI)。其中 AX、BX、CX、DX 可以分成两个 8 位的寄存器来使用,分别是 AH、AL、BH、BL、CH、CL、DH、DL,其中 H 就是 High(高位),L 就是 Low(低位)的意思。
控制单元: IP 寄存器(Instruction Pointer Register)就是指令指针寄存器,它指向代码段中下一条指令的位置。CPU 会根据它来不断地将指令从内存的代码段中,加载到 CPU 的指令队列中,然后交给运算单元去执行。
如果需要切换进程呢?每个进程都分代码段和数据段,为了指向不同进程的地址空间,有四个 16 位的段寄存器,分别是 CS、DS、SS、ES。
其中,CS 就是代码段寄存器(Code Segment Register),通过它可以找到代码在内存中的位置;DS 是数据段的寄存器(Data Segment Register),通过它可以找到数据在内存中的位置。SS 是栈寄存器(Stack Register)。栈是程序运行中一个特殊的数据结构,数据的存取只能从一端进行,秉承后进先出的原则。ES是扩展段寄存器(Extra Segment Register)顾名思义。
如果 CPU 运算中需要加载内存中的数据,需要通过 DS 找到内存中的数据,加载到通用寄存器中,应该如何加载呢?对于一个段,有一个起始的地址,而段内的具体位置,我们称为偏移量(Offset)。在 CS 和 DS 中都存放着一个段的起始地址。代码段的偏移量在 IP 寄存器中,数据段的偏移量会放在通用寄存器中。因为段寄存器都是 16 位的,而地址总线是 20 位的,所以通过 *起始地址 16+ 偏移量 的方式,将寻址位数都变成 20 位,也就是将 CS 和 DS 的值左移 4 位。
对于只有 20 位地址总线的 8086 来说,寻址空间最大也就是$2^{20}=1\text{M}$,超过这个位置就访问不到了,一个段因为偏移量只有 16 位,所以一个段最大是$2^{16}=64\text{k}$。
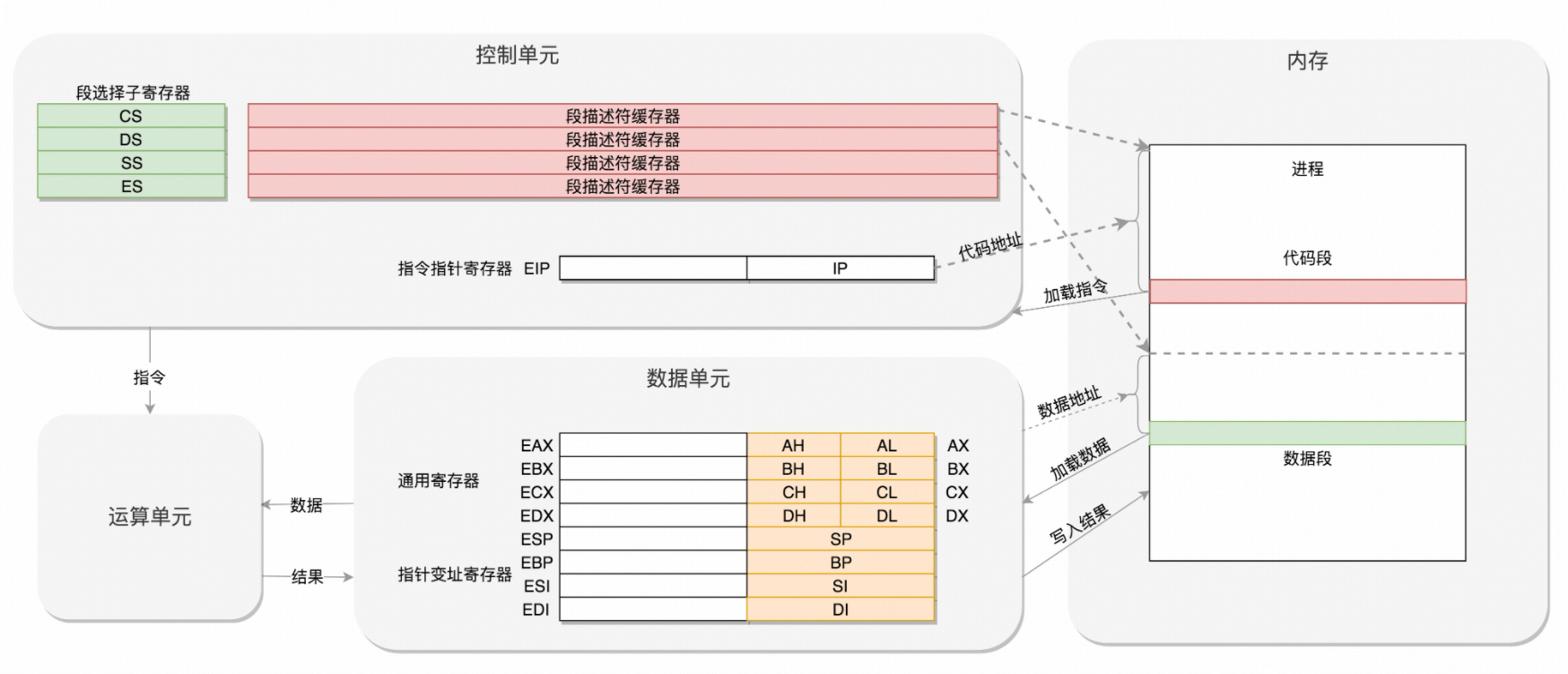
32 位处理器
随着计算机发展,内存越来越大,总线也越来越宽。在 32 位处理器中,有 32 根地址总线,可以访问 $2^{32}=4\text{G}$ 的内存。使用原来的模式肯定不行了,但是又不能完全抛弃原来的模式,因为这个架构是开放的。那么在开发架构的基础上如何保持兼容呢?
首先,通用寄存器有扩展,可以将 8 个 16 位的扩展到 8 个 32 位的,但是依然可以保留 16 位的和 8 位的使用方式。其中,指向下一条指令的指令指针寄存器 IP,就会扩展成 32 位的,同样也兼容 16 位的。

段寄存器改动较大,新的段寄存器都改成了 32 位的,每个寄存器又分为段描述符缓存器(Segment Descriptor),和段选择子寄存器(Selector) ,现在的段寄存器不在是段的起始地址,段的起始地址保存在表格一样的段描述符缓冲器中,段选择子寄存器保存地址在段描述符缓存器中的哪一项。这样,将一个从段寄存器直接拿到的段起始地址,就变成了先间接地从段寄存器找到表格中的一项,再从表格中的一项中拿到段起始地址。
虽然现在的这种模式和之前的模式不兼容,但是后面这种模式灵活的非常高,可以保持一直兼容下去。在 32 位的系统架构下,将前一种模式称为实模式(Real Pattern),后一种模式称为保护模式(Protected Pattern) 。当系统刚刚启动的时候,CPU 是处于实模式的,这个时候和原来的模式是兼容的。也就是说,哪怕你买了 32 位的 CPU,也支持在原来的模式下运行。
汇编命令学习 mov, call, jmp, int, ret, add, or, xor, shl, shr, push, pop, inc, dec, sub, cmp。
BIOS 与 BootLoader
BIOS:基本输入输出系统
ROM:只读存储器
RAM:随机存取存储器
在我们按下电脑电源键的那一刻,主板就加电了,CPU 就要开始执行指令了,但是刚开始操作系统都没,CPU 执行什么指令呢?这就有了BIOS,它相当于一个指导手册,告诉 CPU 接下来要干啥。
刚开机时,系统初始化代码从 ROM 读取,将 CS 设置为 0xFFFF,将 IP 设置为 0x0000,所以第一条指令就会指向 0xFFFF0,初始化完成后确定访问指令位置。
接下来 BIOS 会检查各个硬件是否正常,检测内容显卡等关键部件的存在于工作状态,设备初始化,执行系统 BIOS 进行系统检测,更新 CMOS 中的扩展系统配置数据 ESCD。这期间也会建立中断向量表和中断服务程序,因为要使用键盘鼠标都需要中断进行。
下一步 BIOS 就得要找操作系统了,操作系统一般安装在硬盘上,但是 BIOS 得先找到启动盘,启动盘一般安装在第一个扇区,占 512 字节,会包含启动的相关代码。在 Linux 中,可以通过Grub2配置这些代码。
grub2-mkconfig -o /boot/grub2/grub.cfg
grub2第一个要安装的就是boot.img。它由 boot.S编译而成,一共 512 字节,正式安装到启动盘的第一个扇区。这个扇区通常称为MBR(Master Boot Record,主引导记录 / 扇区)。
BIOS 完成任务后,会将 boot.img 从硬盘加载到内存中的 0x7c00来运行。
由于 512 个字节实在有限,boot.img 做不了太多的事情。它能做的最重要的一个事情就是加载grub2 的另一个镜像 core.img。
core.img 由lzma_decompress.img、diskboot.img、kernel.img 和一系列的模块组成,功能比较丰富,能做很多事情。
boot.img 先加载的是 core.img 的第一个扇区。如果从硬盘启动的话,这个扇区里面是diskboot.img,对应的代码是 diskboot.S。
boot.img 将控制权交给 diskboot.img 后,diskboot.img 的任务就是将core.img 的其他部分加载进来,先是解压缩程序 lzma_decompress.img,再往下是 kernel.img,最后是各个模块module对应的映像。这里需要注意,它不是 Linux 的内核,而是grub 的内核。
在这之前,我们所有遇到过的程序都非常非常小,完全可以在实模式下运行,但是随着我们加载的东西越来越大,实模式这1M 的地址空间实在放不下了,所以在真正的解压缩之前,lzma_decompress.img 做了一个重要的决定,就是调用 real_to_prot,切换到保护模式,这样就能在更大的寻址空间里面,加载更多的东西。
BIOS将加载程序从硬盘的引导扇区加载到指定位置,再跳转到指定位置,将控制权转交给加载程序。加载程序将操作系统代码读取到内存,并将控制权转到操作系统。
Q:BIOS-操作系统,中间经过加载程序。为何不直接读取? A:磁盘文件系统多种多样,硬盘出厂时不能限制只能用一种文件系统,而 BIOS 也不能加上识别所有文件系统的代码。所有为了灵活性只读取磁盘的一块,由加载程序来识别磁盘的文件系统。
切换到保护模式后,将会做以下这些事,大多数都与内存访问方式有关。
首先启动分段,就是在内存里面建立段描述符表,将寄存器里面的段寄存器变成段选择子,指向某个段描述符,这样就能实现不同进程的切换了。
接着是启动分页。能够管理的内存变大了,就需要将内存分成相等大小的块。
打开 Gate20,也就是第 21 根地址线的控制线。因为在实模式 8086 下,一共就 20 根地址线,最大访问1M的地址空间。切换保护模式的函数DATA32 call real_to_prot会打开Gate A20。
现在好了,有的是空间了。接下来我们要对压缩过的 kernel.img 进行解压缩,然后跳转到 kernel.img 开始运行。
内核初始化
- start_kernel()
- INIT_TASK(init_task)
- trap_init()
- mm_init()
- sched_init()
- rest_init()
- kernel_thread(kernel_init, NULL,CLONE_FS)
- kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES)
内核的启动从入口函数start_kernel() 开始。在 init/main.c 文件中,start_kernel 相当于内核的 main 函数。打开这个函数,我们会发现,里面是各种各样初始化函数 XXXX_init。
在操作系统里面,先要有个创始进程,有一行指令 set_task_stack_end_magic(&init_task)。这里面有一个参数 init_task,它的定义是 struct task_struct init_task = INIT_TASK(init_task)。它是系统创建的第一个进程,我们称为0号进程。这是唯一一个没有通过fork 或者kernel_thread 产生的进程,是进程列表的第一个。
trap_init()里设置了很多**中断门 (Interrupt Gate)**处理各种中断。
mm_init()初始化内存管理模块,sched_init()初始化调度模块。
vfs_caches_init() 会用来初始化基于内存的文件系统 rootfs。在这个函数里面,会调用 mnt_init()->init_rootfs()。这里面有一行代码,register_filesystem(&rootfs_fs_type)。在 VFS 虚拟文件系统里面注册了一种类型,我们定义为 struct file_system_type rootfs_fs_type。为了兼容各种各样的文件系统,我们需要将文件的相关数据结构和操作抽象出来,形成一个抽象层对上提供统一的接口,这个抽象层就是 VFS(Virtual File System),虚拟文件系统。
最后start_kernel()调用rest_init()来做其他方面的初始化,如初始化 1 号进程,内核态与用户态转化等。
rest_init 的第一大工作是,用 kernel_thread(kernel_init, NULL, CLONE_FS)创建第二个进程,这个是1 号进程。这对操作系统意义非凡,因为他将运行第一个用户进程,一旦有了用户进程,运行模式也将发生改变,之前所有资源都是给一个进程用,现在有了用户进程,就会出现抢夺资源的现象。资源也分核心和非核心资源,具有不同权限的进程可以获取不同的资源。x86提供了分层的权限机制,分成四个Ring,越往里权限越高。
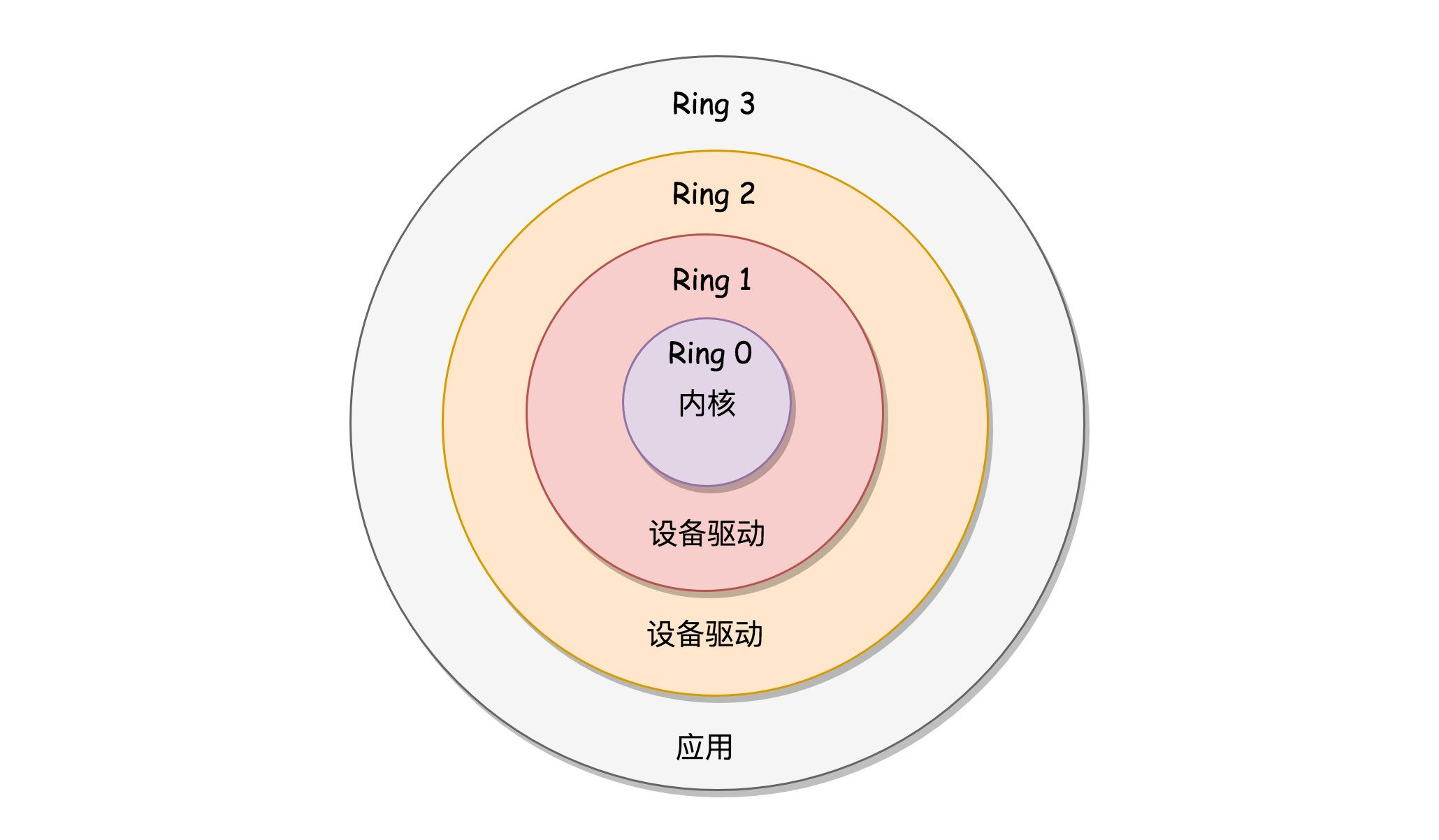
操作系统很好地利用了这个机制,将能够访问关键资源的代码放在 Ring0,我们称为内核态(Kernel Mode);将普通的程序代码放在 Ring3,我们称为用户态(User Mode)。
继续探究kernel_thread()这个函数,它的一个参数有一个函数kernel_init,在这个函数里会调用kernel_init_freeable(),里面有这样一段代码
if (!ramdisk_execute_command)
ramdisk_execute_command = "/init";
先不管ramdisk 是啥,我们回到 kernel_init 里面。这里面有这样的代码块:
if (ramdisk_execute_command) {
ret = run_init_process(ramdisk_execute_command);
....
}
....
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
我们可以发现,1 号进程运行的是一个文件,如果我们打开run_init_process函数,会发现它调用的是do_execve。
前面讲系统调用的时候,execve 是一个系统调用,它的作用是运行一个执行文件。加一个 do_ 的往往是内核系统调用的实现。没错,这就是一个系统调用,它会尝试运行 ramdisk 的“/init”,或者普通文件系统上的“/sbin/init”“/etc/init”“/bin/init”“/bin/sh”。不同版本的 Linux 会选择不同的文件启动,但是只要有一个起来了就可以。
static int run_init_process(const char *init_filename)
{
argv_init[0] = init_filename;
return do_execve(getname_kernel(init_filename),
(const char __user *const __user *)argv_init,
(const char __user *const __user *)envp_init);
}
如何利用执行 init 文件的机会,从内核态回到用户态呢?
我们从系统调用的过程可以得到启发,“用户态 - 系统调用 - 保存寄存器 - 内核态执行系统调用 - 恢复寄存器 - 返回用户态”,然后接着运行。而咱们刚才运行init,是调用 do_execve,正是上面的过程的后半部分,从内核态执行系统调用开始。
do_execve->do_execveat_common->exec_binprm->search_binary_handler,这里面会调用这段内容:
int search_binary_handler(struct linux_binprm *bprm)
{
......
struct linux_binfmt *fmt;
......
retval = fmt->load_binary(bprm);
......
}
也就是说,我要运行一个程序,需要加载这个二进制文件,这就是我们常说的项目执行计划书。它是有一定格式的。Linux 下一个常用的格式是 ELF(Executable and Linkable Format,可执行与可链接格式)。于是我们就有了下面这个定义:
static struct linux_binfmt elf_format = {
.module = THIS_MODULE,
.load_binary = load_elf_binary,
.load_shlib = load_elf_library,
.core_dump = elf_core_dump,
.min_coredump = ELF_EXEC_PAGESIZE,
};
这其实就是先调用 load_elf_binary,最后调用 start_thread。
void
start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp)
{
set_user_gs(regs, 0);
regs->fs = 0;
regs->ds = __USER_DS;
regs->es = __USER_DS;
regs->ss = __USER_DS;
regs->cs = __USER_CS;
regs->ip = new_ip;
regs->sp = new_sp;
regs->flags = X86_EFLAGS_IF;
force_iret();
}
EXPORT_SYMBOL_GPL(start_thread);
struct pt_regs,看名字里的 register,就是寄存器啊!这个结构就是在系统调用的时候,内核中保存用户态运行上下文的,里面将用户态的代码段 CS设置为 __USER_CS,将用户态的数据段 DS 设置为 __USER_DS,以及指令指针寄存器 IP、栈指针寄存器 SP。这里相当于补上了原来系统调用里,保存寄存器的一个步骤。
最后的 iret 是干什么的呢?它是用于从系统调用中返回。这个时候会恢复寄存器。从哪里恢复呢?按说是从进入系统调用的时候,保存的寄存器里面拿出。好在上面的函数补上了寄存器。CS 和指令指针寄存器 IP 恢复了,指向用户态下一个要执行的语句。DS 和函数栈指针 SP 也被恢复了,指向用户态函数栈的栈顶。所以,下一条指令,就从用户态开始运行了。
init 终于从内核到用户态了。一开始到用户态的是 ramdisk 的 init,后来会启动真正根文件系统上的 init,成为所有用户态进程的祖先。
为什么会有 ramdisk 这个东西呢?还记得上一节咱们内核启动的时候,配置过这个参数:
initrd16 /boot/initramfs-3.10.0-862.el7.x86_64.img
就是这个东西,这是一个基于内存的文件系统。为啥会有这个呢?
是因为刚才那个 init 程序是在文件系统上的,文件系统一定是在一个存储设备上的,例如硬盘。Linux 访问存储设备,要有驱动才能访问。如果存储系统数目很有限,那驱动可以直接放到内核里面,反正前面我们加载过内核到内存里了,现在可以直接对存储系统进行访问。
但是存储系统越来越多了,如果所有市面上的存储系统的驱动都默认放进内核,内核就太大了。这该怎么办呢?
我们只好先弄一个基于内存的文件系统。内存访问是不需要驱动的,这个就是 ramdisk。这个时候,ramdisk 是根文件系统。
然后,我们开始运行 ramdisk 上的 /init。等它运行完了就已经在用户态了。/init 这个程序会先根据存储系统的类型加载驱动,有了驱动就可以设置真正的根文件系统了。有了真正的根文件系统,ramdisk上的 /init 会启动文件系统上的 init。
接下来就是各种系统的初始化。启动系统的服务,启动控制台,用户就可以登录进来了。
至此,用户态进程有了一个祖宗,那内核态的进程呢?这就是rest_init接下来要做的是,创建 2 号线程。
kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES)又一次使用 kernel_thread 函数创建进程。这里的函数 kthreadd,负责所有内核态的线程的调度和管理,是内核态所有线程运行的祖先。
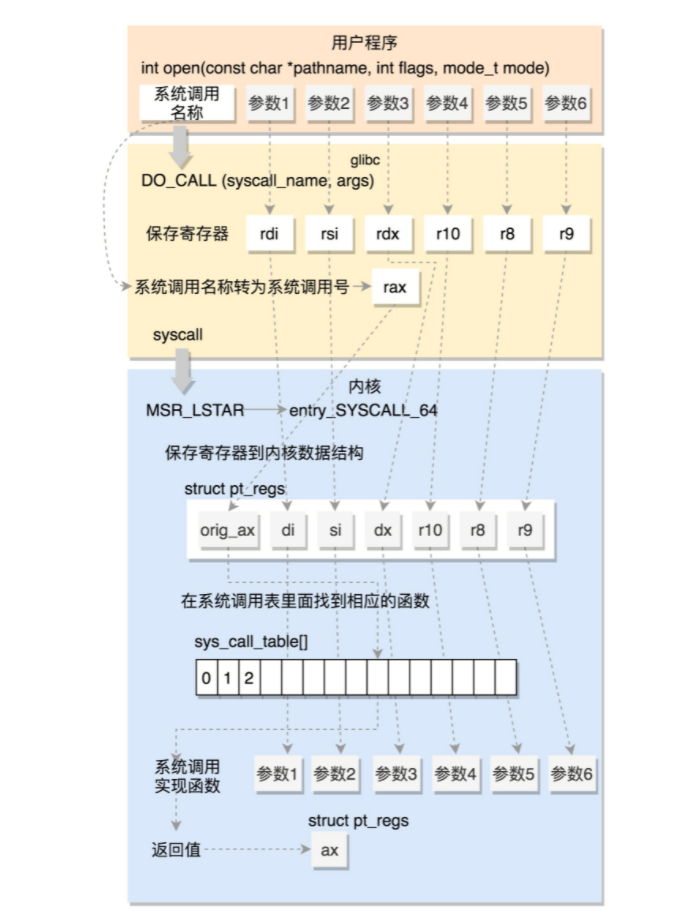
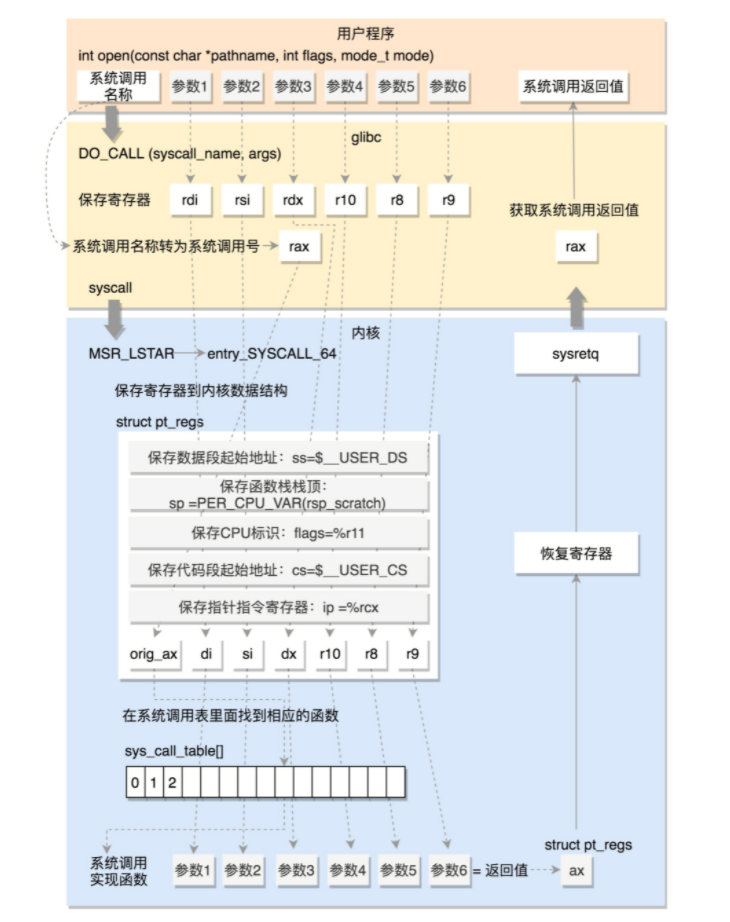
系统调用
Linux 提供了glibc这个库封装了系统调用,方便用户使用。那么在打开一个文件时,glibc是如何调用内核的open的呢?
在 glibc 的源代码中,有个文件syscalls.list,里面列着所有 glibc 的函数对应的系统调用,就像下面这个样子:
# File name Caller Syscall name Args Strong name Weak names
open - open Ci:siv __libc_open __open open
另外,glibc 还有一个脚本 make-syscall.sh,可以根据上面的配置文件,对于每一个封装好的系统调用,生成一个文件。这个文件里面定义了一些宏,例如 #define SYSCALL_NAME open。
glibc 还有一个文件 syscall-template.S,使用上面这个宏,定义了这个系统调用的调用方式。
对于任何一个系统调用,会调用DO_CALL。这也是一个宏,这个宏 32 位和 64 位的定义是不一样的。
32 位系统调用过程
i386 目录下的sysdep.h 文件
/* Linux takes system call arguments in registers:
syscall number %eax call-clobbered
arg 1 %ebx call-saved
arg 2 %ecx call-clobbered
arg 3 %edx call-clobbered
arg 4 %esi call-saved
arg 5 %edi call-saved
arg 6 %ebp call-saved
......
*/
#define DO_CALL(syscall_name, args)
PUSHARGS_##args
DOARGS_##args
movl $SYS_ify (syscall_name), %eax;
ENTER_KERNEL
POPARGS_##args
这里,我们将请求参数放在寄存器里面,根据系统调用的名称,得到系统调用号,放在寄存器 eax 里面,然后执行 ENTER_KERNEL。
# define ENTER_KERNEL int $0x80
ENTER_KERNEL就是一个软中断,通过它可以陷入 (trap) 内核。
在内核启动的时候,还记得有一个 trap_init(),这是一个软中断的陷入门。当接到一个系统调用时,trap_init()就会调用entry_INT80_32。
通过 push 和 SAVE_ALL 将当前用户态的寄存器,保存在 pt_regs 结构里面,然后调用 do_syscall_32_irqs_on。

64 位系统调用过程