存储器的层次结构
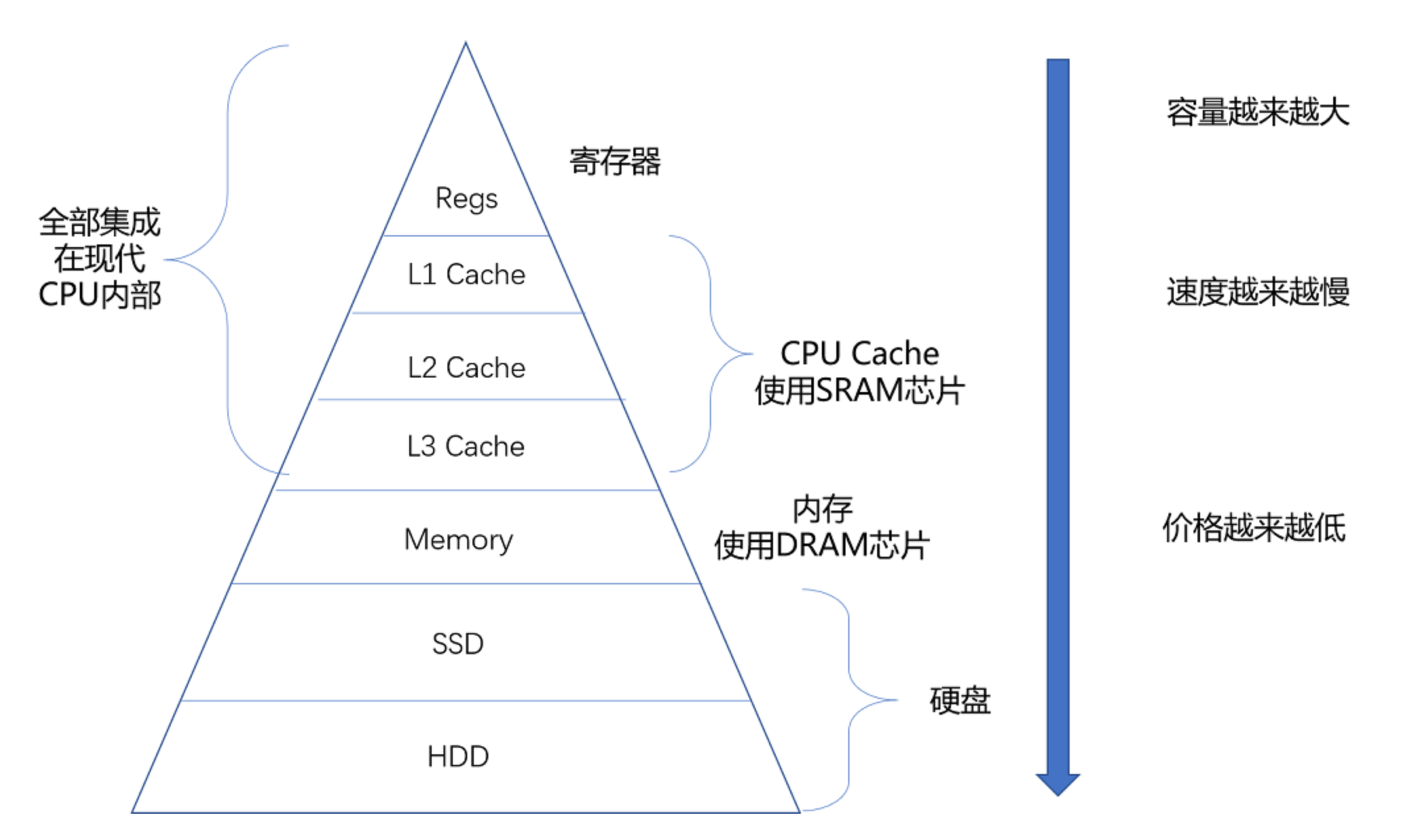
从 Cache、内存,到 SSD 和 HDD 硬盘,一台现代计算机中,就用上了所有这些存储器设备。其中,容量越小的设备速度越快,而且,CPU 并不是直接和每一种存储器设备打交道,而是每一种存储器设备,只和它相邻的存储设备打交道。比如,CPUCache 是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到 CPUCache 中,而是先加载到内存,再从内存加载到 Cache 中。
这样,各个存储器只和相邻的一层存储器打交道,并且随着一层层向下,存储器的容量逐层增大,访问速度逐层变慢,而单位存储成本也逐层下降,也就构成了我们日常所说的存储器层次结构。
高速缓存
缓存不是 CPU 的专属功能,可以把它当成一种策略,任何时候想要增加数据传输性能,都可以通过加一层缓存试试。
存储器层次结构的中心思想是,对于每个$k$,位于$k$层的更快更小的存储设备作为位于$k+1$层的更大更慢的存储设备的缓存。下图展示了存储器层次结构中缓存的一般性概念。
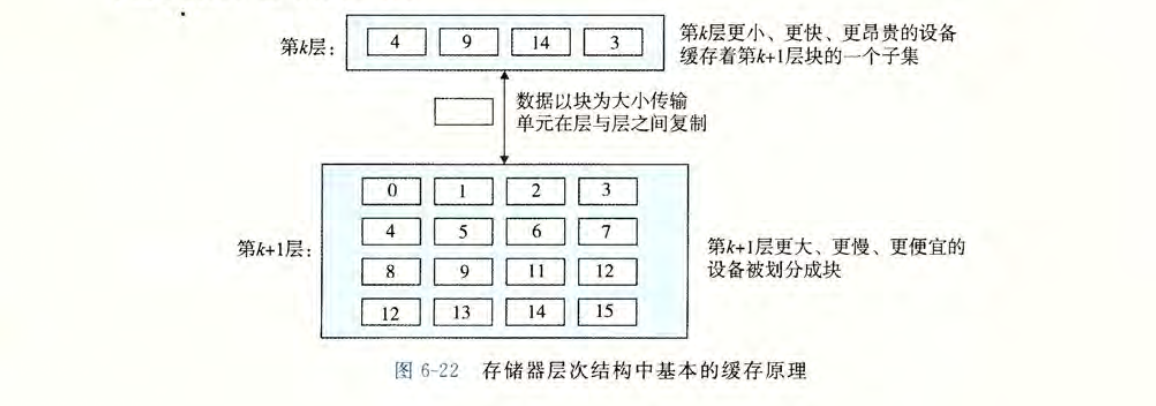
数据总是以块block为单位,在层与层之间来回复制。
说回高速缓存,按照摩尔定律,CPU 的访问速度每 18 个月便会翻一翻,相当于每年增长 60%。内存的访问速度虽然不断增长,却远没有那么快,每年只增长 7% 左右。这样就导致 CPU 性能和内存访问的差距不断拉大。为了弥补两者之间差异,现代 CPU 引入了高速缓存。
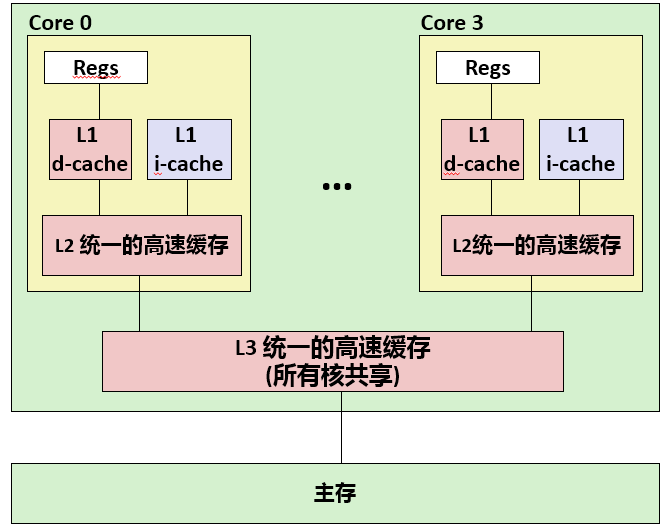
CPU 的读(load)实质上就是从缓存中读取数据到寄存器(register)里,在多级缓存的架构中,如果缓存中找不到数据(Cache miss),就会层层读取二级缓存三级缓存,一旦所有的缓存里都找不到对应的数据,就要去内存里寻址了。寻址到的数据首先放到寄存器里,其副本会驻留到 CPU 的缓存中。
CPU 的写(store)也是针对缓存作写入。并不会直接和内存打交道,而是通过某种机制实现数据从缓存到内存的写回(write back)。
缓存到底如何与 CPU 和主存数据交换的?CPU 如何从缓存中读写数据的?缓存中没有读的数据,或者缓存写满了怎么办?我们先从 CPU 如何读取数据说起。
缓存读取
CPU 发起一个读取请求后,返回的结果会有如下几种情况:
- 缓存命中 (cache hit) 要读取的数据刚好在缓存中,叫做缓存命中。
- 缓存不命中 (cache miss)
发送缓存不命中,缓存就得执行一直放置策略(placement policy),比如 LRU。来决定从主存中取出的数据放到哪里。
- 强制性不命中(compulsory miss)/冷不命中(cold miss):缓存中没有要读取的数据,需要从主存读取数据,并将数据放入缓存。
- 冲突不命中(conflict miss):缓存中有要读的数据,在采取放置策略时,从主存中取数据放到缓存时发生了冲突,这叫做冲突不命中。
高速缓存存储器组织结构
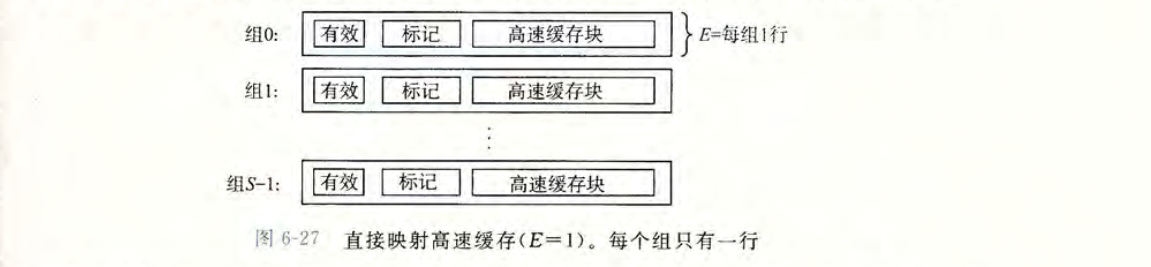
整个 Cache 被划分为 1 个或多个组 (Set),$S$ 表示组的个数。每个组包含 1 个或多个缓存行(Cache line),$E$ 表示一个组中缓存行的行数。每个缓存行由三部分组成:有效位(valid),标记位(tag),数据块(cache block)。
- 有效位:该位等于 1,表示这个行数据有效。
- 标记位:唯一的标识了存储在高速缓存中的块,标识目标数据是否存在当前的缓存行中。
- 数据块:一部分内存数据的副本。

Cache 的结构可以由元组$(S,E,B,m)$表示。不包括有效位和标记位。Cache 的大小为 $C=S \times E \times B$.
接下来看看 Cache 是如何工作的,当 CPU 执行数据加载指令,从内存地址 A 读取数据时,根据存储器层次原理,如果 Cache 中保存着目标数据的副本,那么就立即将数据返回给 CPU。那么 Cache 如何知道自己保存了目标数据的副本呢?
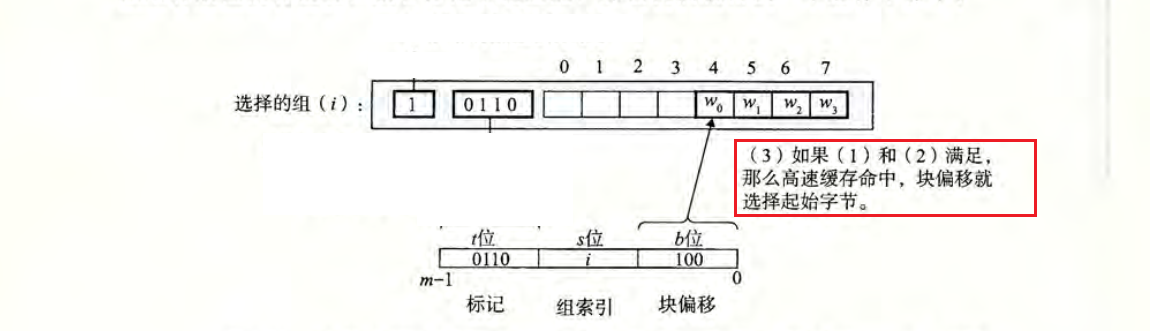
假设目标地址的数据长度为$m$位,这个地址被参数 $S$ 和 $B$ 分成了三个字段:

首先通过长度为$s$的组索引,确定目标数据保存在哪一个组 (Set) 中,其次通过长度为$t$的标记,确定在哪一行,需要注意的是此时有效位必须等于 1,最后根据长度为$b$的块偏移,来确定目标数据在数据块中的确切位置。
Q:既然读取 Cache 第一步是组选择,为什么不用高位作为组索引,而使用中间的为作为组索引? A:如果使用了高位作索引,那么一些连续的内存块就会映射到相同的高速缓存块。如图前四个块映射到第一个缓存组,第二个四个块映射到第二个组,依次类推。如果一个程序有良好的空间局部性,顺序扫描一个数组的元素,那么在任何时候,缓存中都只保存在一个块大小的数组内容。这样对缓存的使用率很低。相比而言,如果使用中间的位作为组索引,那么相邻的块总是映射到不同的组,图中的情况能够存放整个大小的数组片。
Responsive Image

直接映射高速缓存 Direct Mapped Cache
根据每个组的缓存行数 $E$ 的不同,Cache 被分为不同的类。每个组只有一行$E=1$的高速缓存被称为直接映射高速缓存(direct-mapped cache)。
当一条加载指令指示 CPU 从主存地址 A 中读取一个字 w 时,会将该主存地址 A 发送到高速缓存中,则高速缓存会根据组选择,行匹配和字抽取三步来判断地址 A 是否命中。
组选择(set selection):根据组索引值来确定属于哪一个组,如图中索引长度为 5 位,可以检索 32 个组 ($2^5=32$)。当$s=0$时,此时组选择的结果为set 0,当$s=1$时,此时组选择的结果为set 1。

行匹配 (line match):首先看缓存行的有效位,此时有效位为 1,表示当前数据有效。然后对比缓存行的标记0110与地址中的标记0110是否相等,如果相等,则表示目标数据在当前的缓存行中(缓存命中)。如果不一致或者有效位为 0,则表示目标数据不在当前的缓存行中(缓存不命中)。如果命中,就可以进行下一步字抽取。

字抽取 (word extraction):根据偏移量$b$确定目标数据的确切位置,通俗来说就是从数据块的什么位置开始抽取位置。如当偏移块等于100时,表示目标数据起始地址位于字节 4 处。
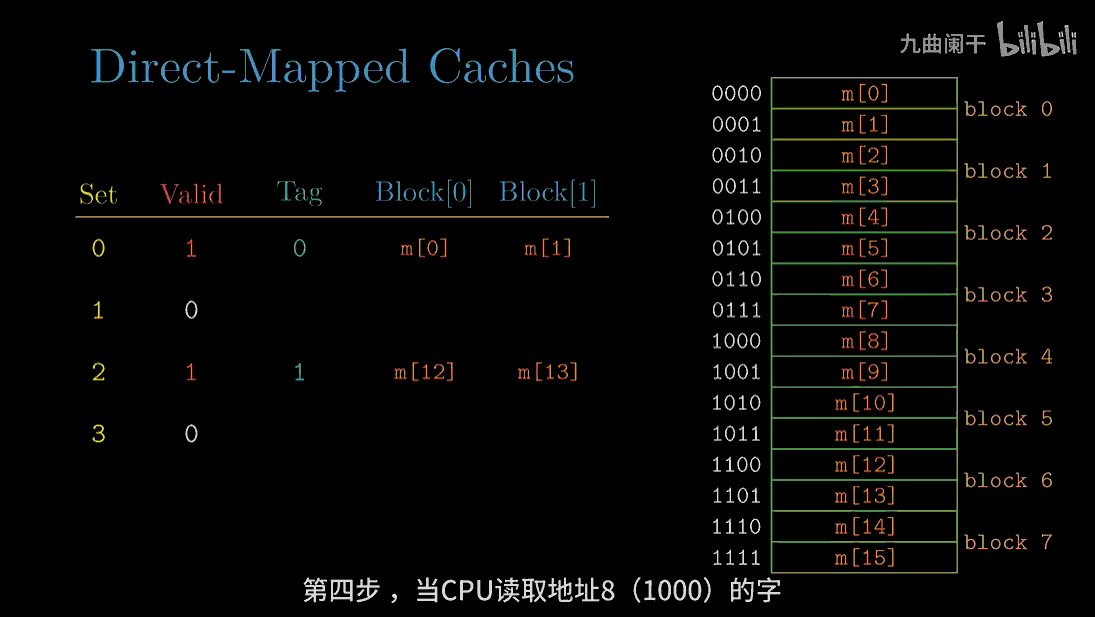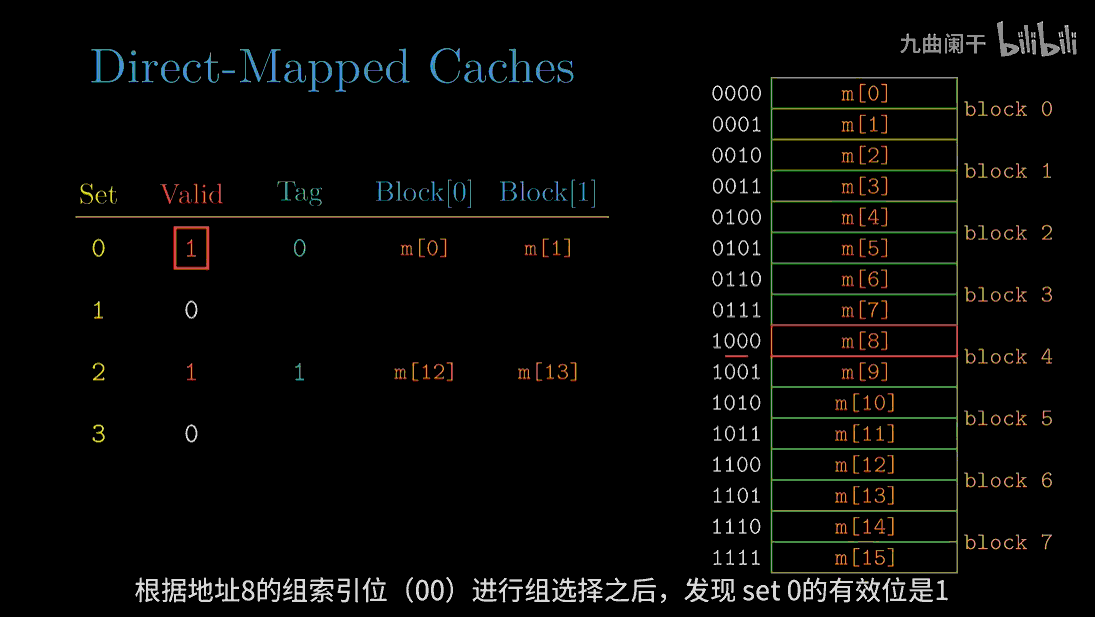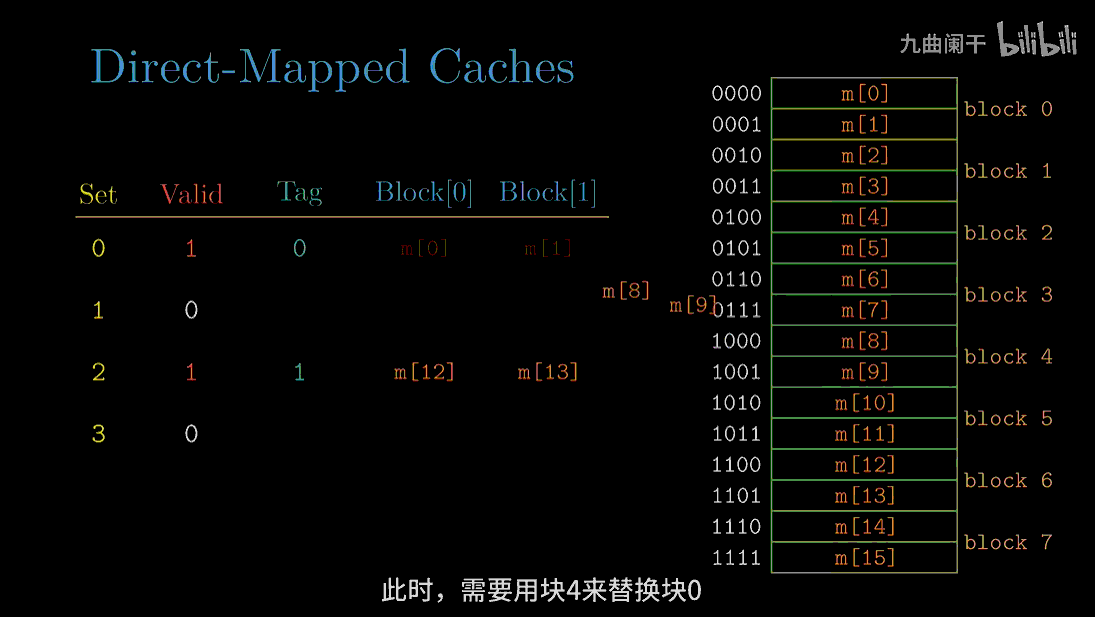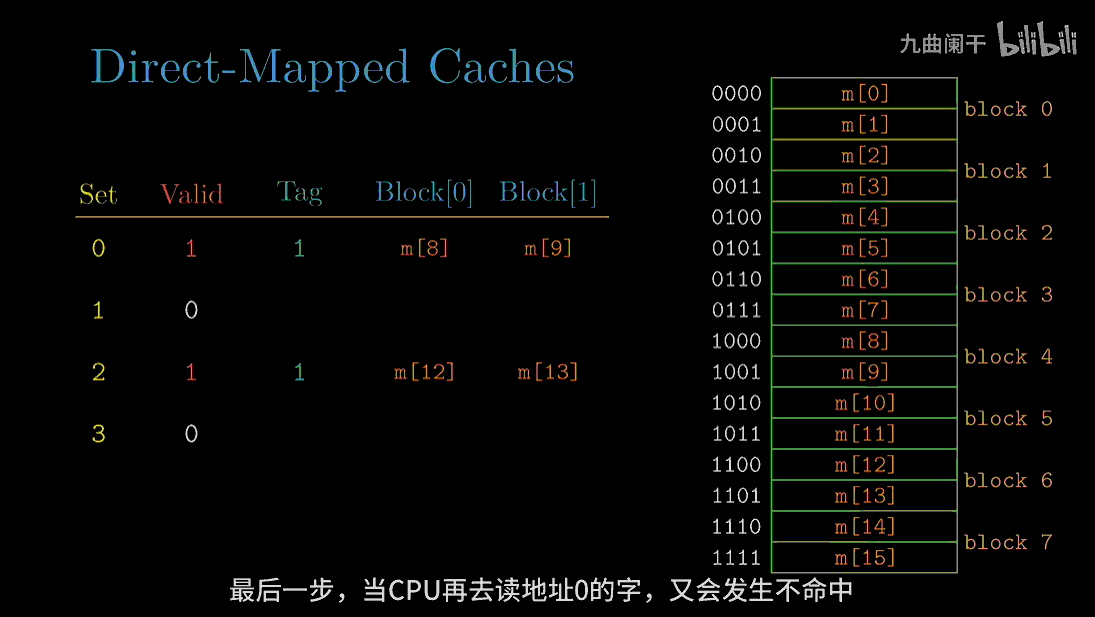
下面通过一个例子来解释清除这个过程。假设我们有一个直接映射高速缓存,描述为$(S,E,B,m) = (4,1,2,4)$。换句话说,高速缓存有 4 个组,每个组 1 行,每个数据块 2 个字节,地址长度为 4 位。
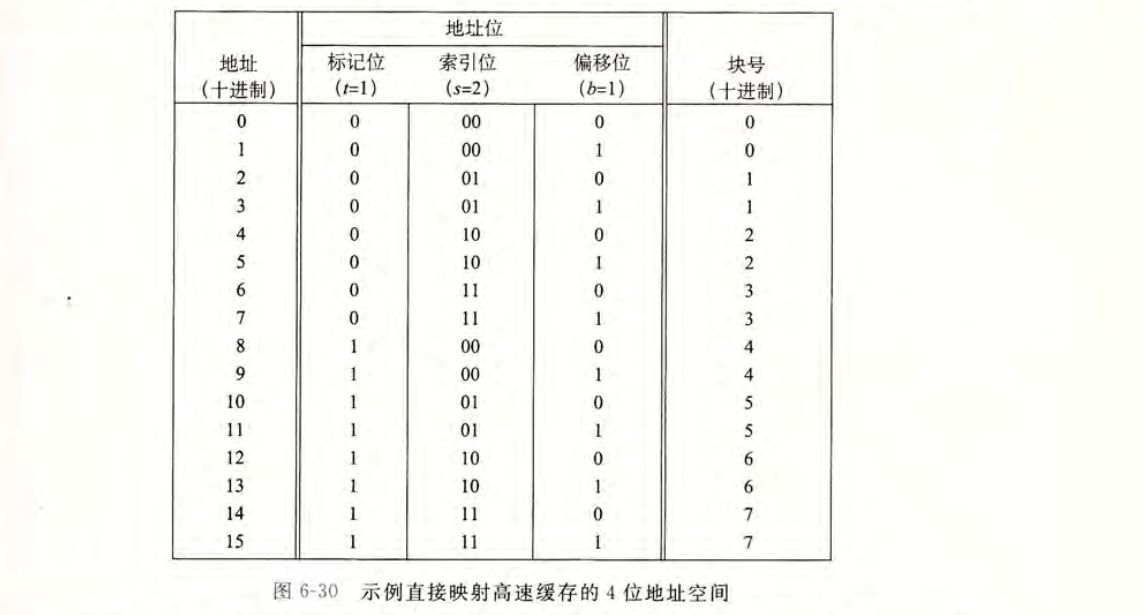
从图中可以看出,8 个内存块,但只有 4 个高速缓存组,所以会有多个块映射到同一个高速缓存组中。例如,块 0 和块 4 都会被映射到组 0。
下面我们来模拟当 CPU 执行一系列读的时候,高速缓存的执行情况,我们假设每次 CPU 读 1 个字节的字。
读地址 0(0000) 的字:
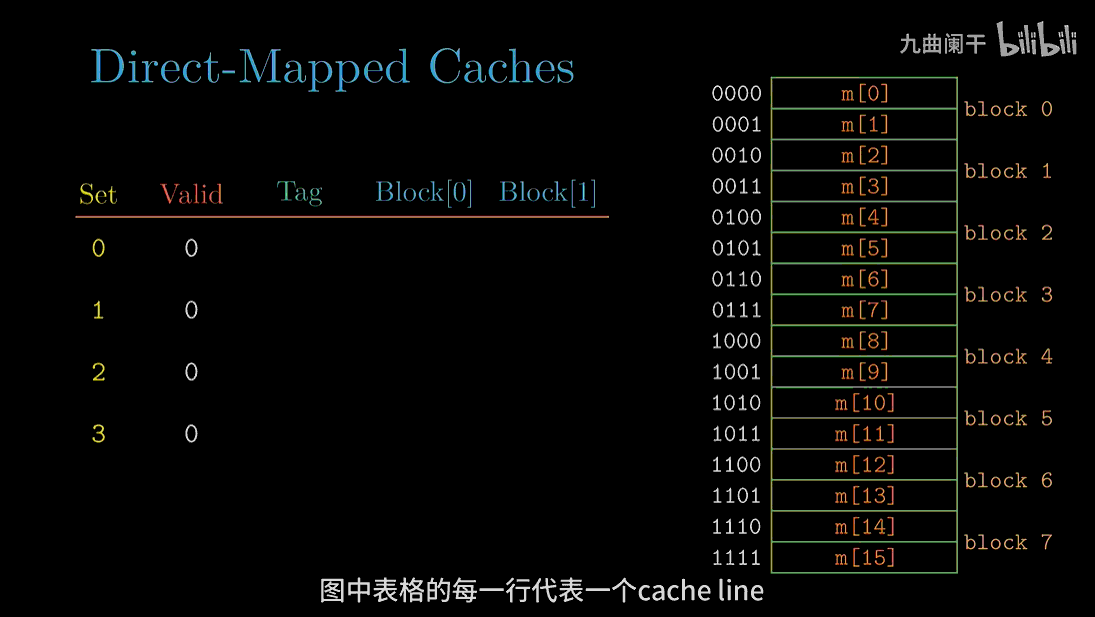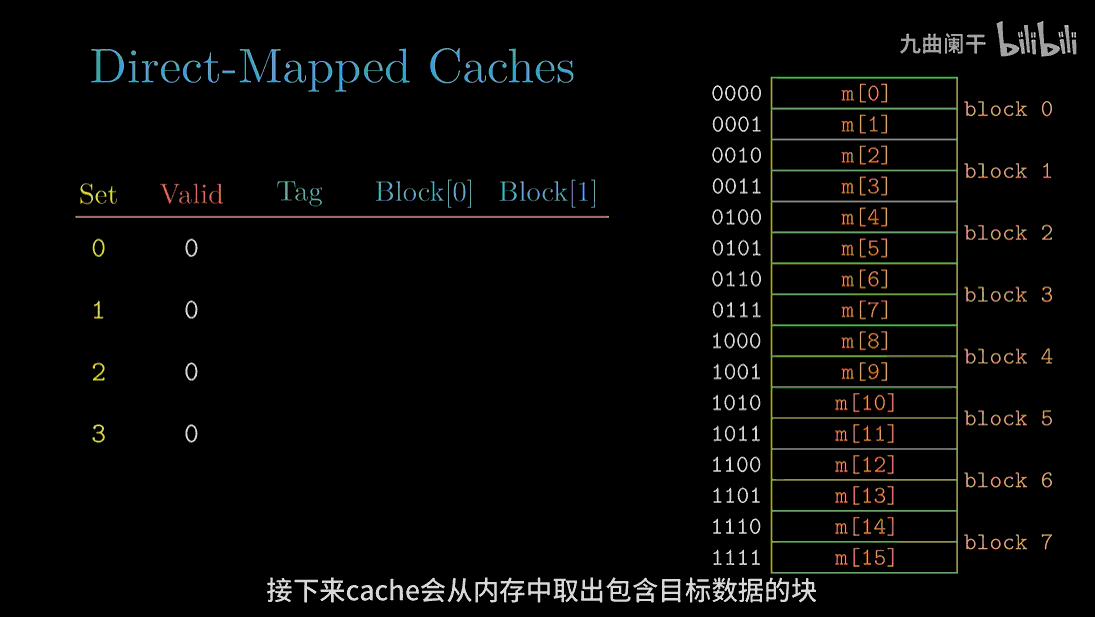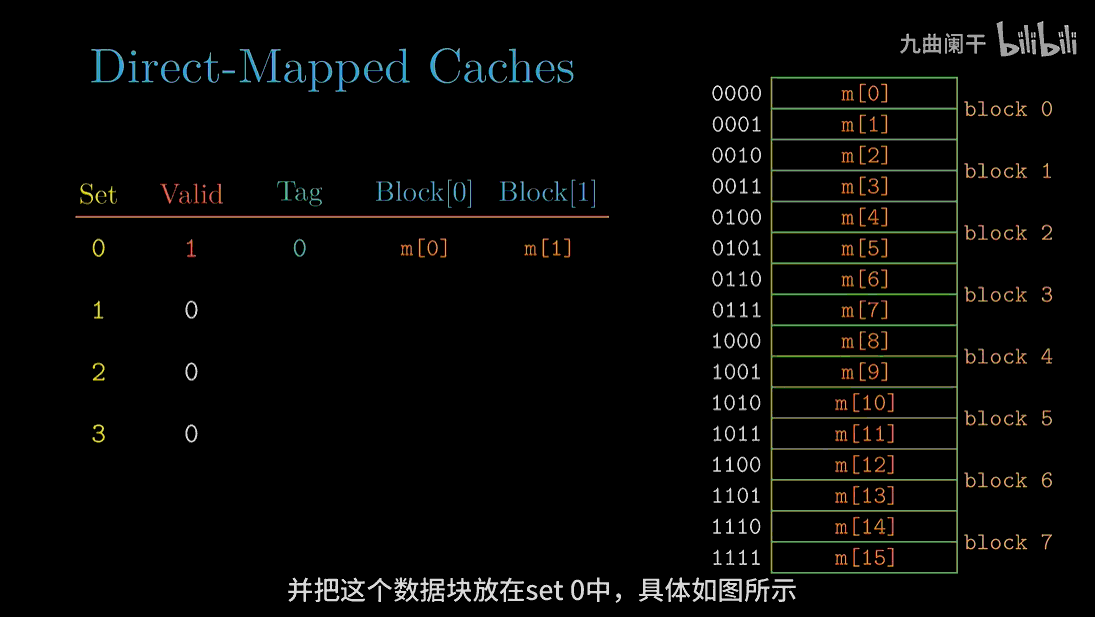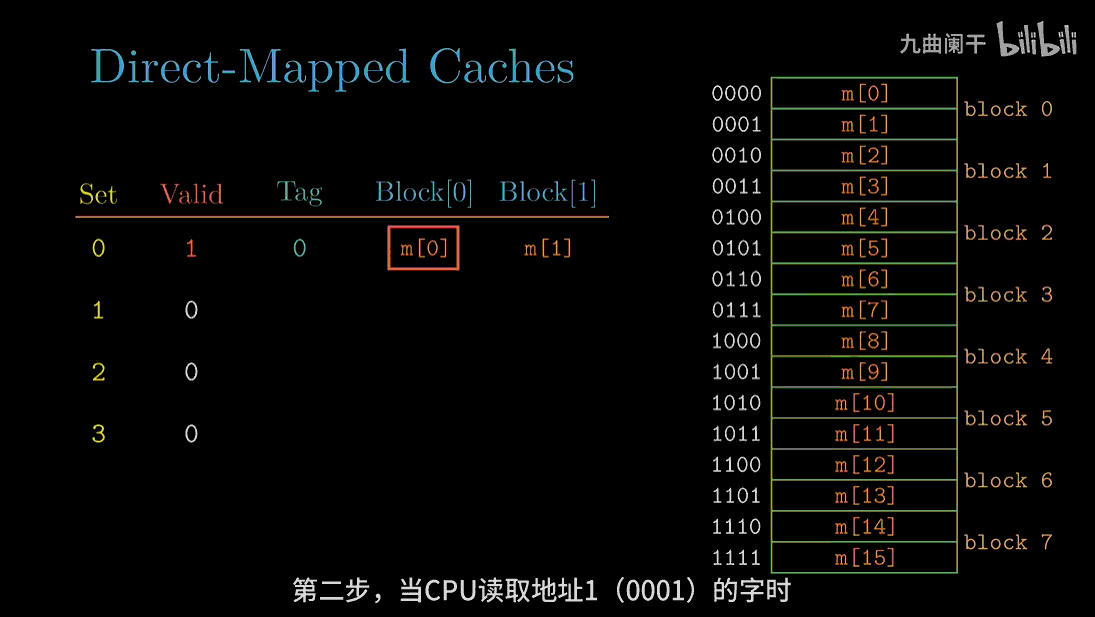
读地址 1(0001) 的字:

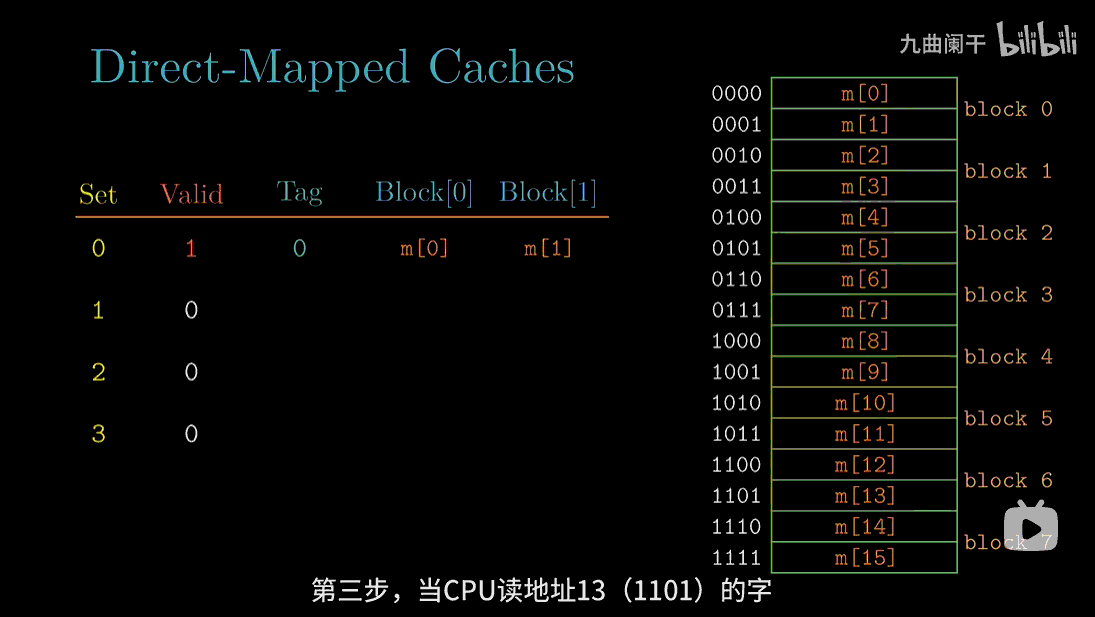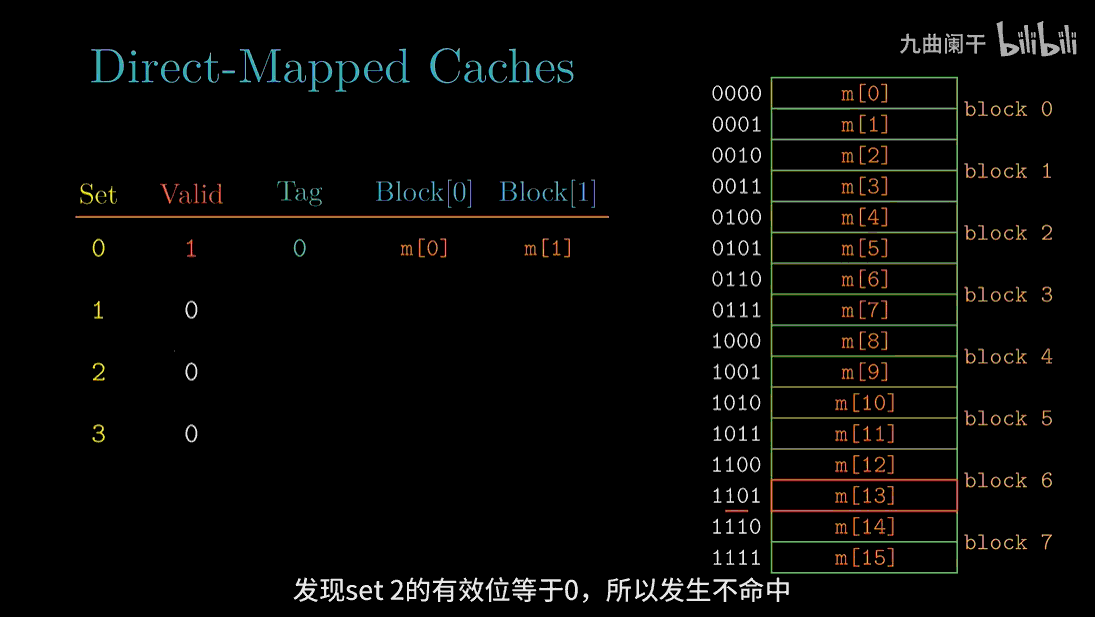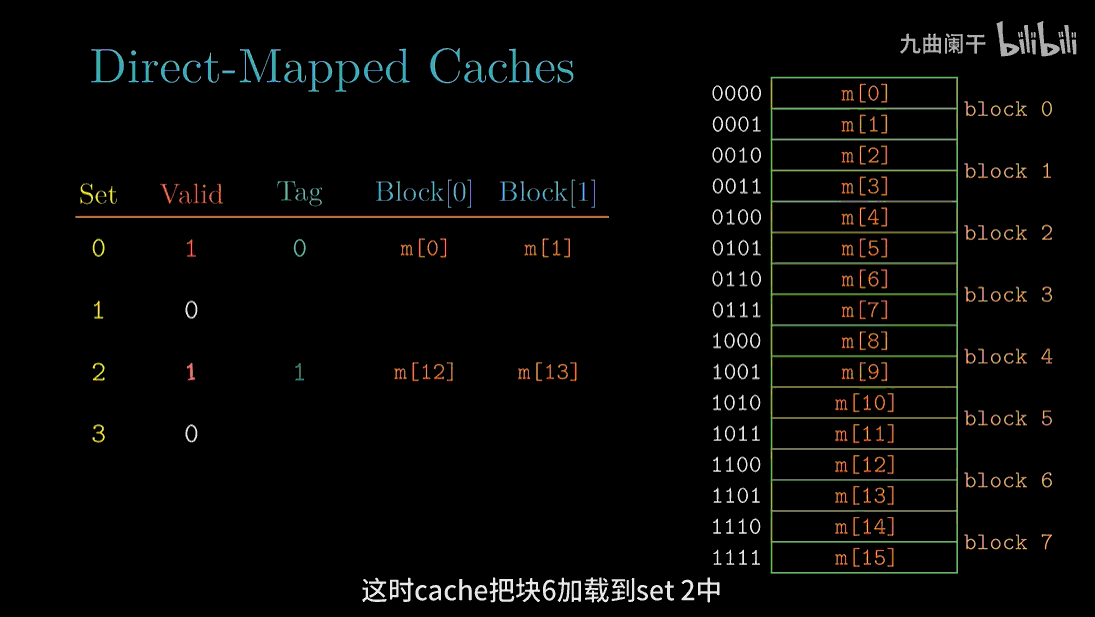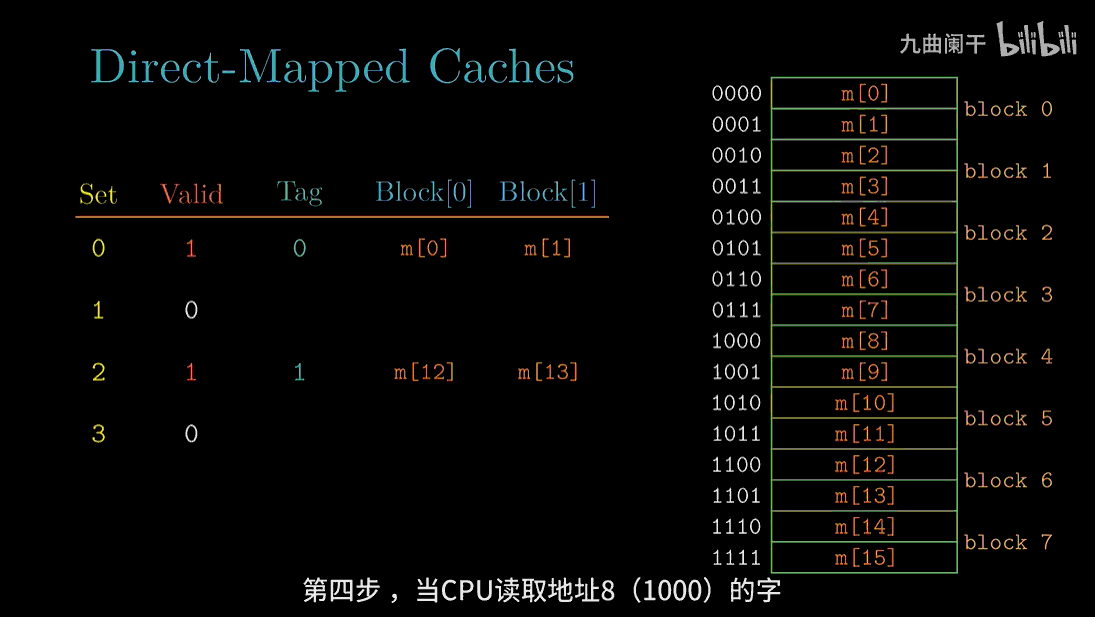
读地址 13(1101) 的字:
读地址 8(1000) 的字:
读地址 0(0000) 的字:

组相联高速缓存 Set Associative Cache
由于直接映射高速缓存的组中只有一行,所以容易发生冲突不命中。组相联高速缓存 (Set associative cache) 运行有多行缓存行。但是缓存行最大不能超过 $C/B$。
如图一个组中包含了两行缓存行,这种我们称为 2 路相联高速缓存。
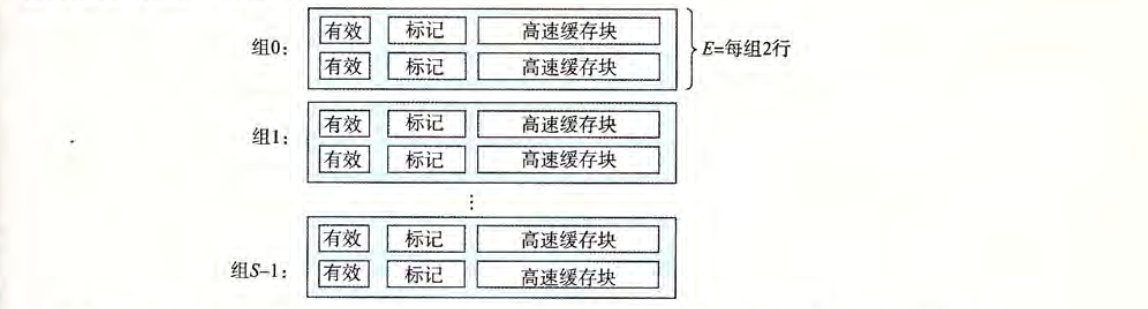
组选择:与直接映射高速缓存的组选择过程一样。
行匹配:因为一个组有多行,所以需要遍历所有行,找到一个有效位为 1,并且标记为与地址中的标记位相匹配的一行。如果找到了,表示缓存命中。
字抽取:根据偏移量$b$确定目标数据的确切位置,通俗来说就是从数据块的什么位置开始抽取位置。如当偏移块等于100时,表示目标数据起始地址位于字节 4 处。
如果不命中,那么就需要从主存中取出需要的数据块,但是将数据块放在哪一行缓存行呢?如果存在空行 ($valid=0$),那就放到空行里。如果没有空行,就得选择一个非空行来替换,同时希望 CPU 不会很快引用这个被替换的行。这里介绍几个替换策略。
最简单的方式就是随机选择一行来替换,其他复杂的方式就是利用局部性原理,使得接下来 CPU 引用替换的行概率最小。如
- 最不常使用 (LFU, Least Frequently Used),选择使用次数最少的行。
- 最近最少使用 (LRU, Least Recently Used),选择最近使用最少的行。
全相联高速缓存 Fully Associative Cache
整个 Cache 只有一个组,这个组包含了所有的缓存行。

组选择:因为只有一个组,所有默认总是选择 set 0。实际上这不就直接可以忽略了,访问的地址也就只需要划分为标记和偏移。
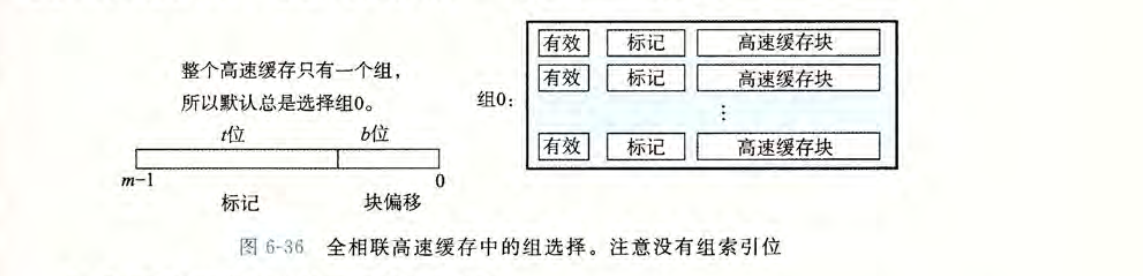
行匹配:同组相联高速缓存。
字抽取:同组相联高速缓存。
由于硬件实现及成本等原因,全相联高速缓存只适合做小规模的缓存。例如虚拟内存中的 TLB(翻译备用缓存器,Translation Lookaside Buffer)。
缓存写入
写入 Cache 的性能比写入主内存要快,那么写入数据到底是写入 Cache 还是写入主内存呢?如果直接写入主内存里,Cache 里面的数据是否会失效呢?
写直达
写直达策略(Write-Through):当数据要写入主内存里面,写入前,会先去判断数据是否已经在 Cache 里面了。如果数据已经在 Cache 里了,先把数据写入更新到 Cache 里面,再写入到主内存里面;如果数据不在 Cache 里,就只更新主内存。
写回
写回策略(Write-Back):如果发现要写入的数据,就在 CPU Cache 里面,那么就只是更新 CPU Cache 里面的数据。同时,会标记 CPU Cache 里的这个 Block 是脏(Dirty)的,表示 CPU Cache 里面的这个 Block 的数据,和主内存是不一致的。如果发现,要写入的数据所对应的 Cache Block 里,放的是别的内存地址的数据,那么就要看一看,那个 Cache Block 里面的数据有没有标记成脏的。如果是脏的话,要先把这个 Cache Block 里面的数据,写入到主内存里面。然后,再把当前要写入的数据,写入到 Cache 里,同时把 Cache Block 标记成脏的。如果 Block 里面的数据没有被标记成脏的话,那么直接把数据写入到 Cache 里面,然后再把 Cache Block 标记成脏的就好了。
在用了写回这个策略之后,在加载内存数据到 Cache 里面的时候,也要多出一步同步脏 Cache 的动作。如果加载内存里面的数据到 Cache 的时候,发现 Cache Block 里面有脏标记,也要先把 Cache Block 里的数据写回到主内存,才能加载数据覆盖掉 Cache。
缓存一致性
参考资料
C/C++中 volatile 关键字详解 - chao_yu - 博客园 volatile 能解决 cache 的数据一致性吗?答案是不能_天才 2012 的博客-CSDN 博客_volatilewritecache cpu 缓存和 volatile - XuMinzhe - 博客园 【CSAPP-深入理解计算机系统】6-5. 直接映射高速缓存_哔哩哔哩_bilibili 24 张图 7000 字详解计算机中的高速缓存 - 腾讯云开发者社区 - 腾讯云