在这个系列文章的第一部分中,我们讨论了 ECAM 以及软件和硬件数据包网络中的配置空间访问。在讨论中,引入了 TLP(Transaction Layer Packets)的概念,这是所有 PCIe 数据在层次结构中移动的通用数据包结构。我们还讨论了这些数据包如何像以太网一样传输,即路由设备使用一个地址(在这种情况下是 BDF)来发送配置空间数据包穿过网络。
配置空间读取和写入只是可以直接使用设备执行 I/O 的几种方式之一。通过“configuration”这个名称,我们可以知道很明显它的意图不是为了执行大量数据传输。主要缺点是它的速度,因为配置空间数据包最多只能包含双向读取或写入的 64 位数据(通常只有 32 位)。对于如此少量的可用数据,数据包和其他链路标头的开销非常大,因此浪费了带宽。
正如第 1 部分所讨论的,理解内存和地址将继续是理解 PCIe 的关键。在这篇文章中,我们将更深入地研究更快的设备 I/O 事务形式,并开始了解软件设备驱动程序如何实际与 PCIe 设备连接以完成有用的工作。
注意:您无需成为计算机体系结构或 TCP/IP 网络方面的专家即可从这篇文章中获得一些信息。但是,了解 TCP/IP 和虚拟内存的基础知识对于掌握本文的一些核心概念是必要的。这篇文章也以 第 1 部分 中的信息为基础。如果您需要查看这些内容,请立即查看!
PCIe 中的数据传输方法简介
配置空间是一种在枚举时间内通过其 BDF 与设备通信的一种简单而有效的方式。这是一种简单的传输模式是有原因的 - 它必须是配置和可用的所有其他数据传输方法的基础。枚举设备后,配置空间已设置设备与主机一起执行实际工作所需的所有信息。配置空间仍用于允许主机监控和响应设备及其链接状态的变化,但它不会用于执行设备的实际高速传输或功能。
配置空间是在枚举时间通过设备的 BDF 进行通信的一种简单有效的方式。它是一种简单的传输模式,是所有数据传输方法的基础。一旦设备被枚举,配置空间就已经设置了设备执行实际工作所需的所有信息,与主机机器一起。配置空间仍用于允许主机计算机监视和响应设备及其链接的变化,但不会用于执行设备的实际高速传输或功能。
我们现在需要的是数据传输方法,让我们真正开始利用 PCIe 设计的高速传输吞吐量。吞吐量是对给定时间段内传输的字节数的度量。这意味着为了最大限度地提高吞吐量,我们必须最小化每个数据包的开销,以传输每个数据包的最大字节数。如果我们每个数据包只发送几个 DWORD(每个 4 字节),就像在配置空间的情况下一样,PCIe 高速传输能力就浪费了。
废话不多说,先介绍一下 PCIe 中高速 I/O 的两种主要形式:
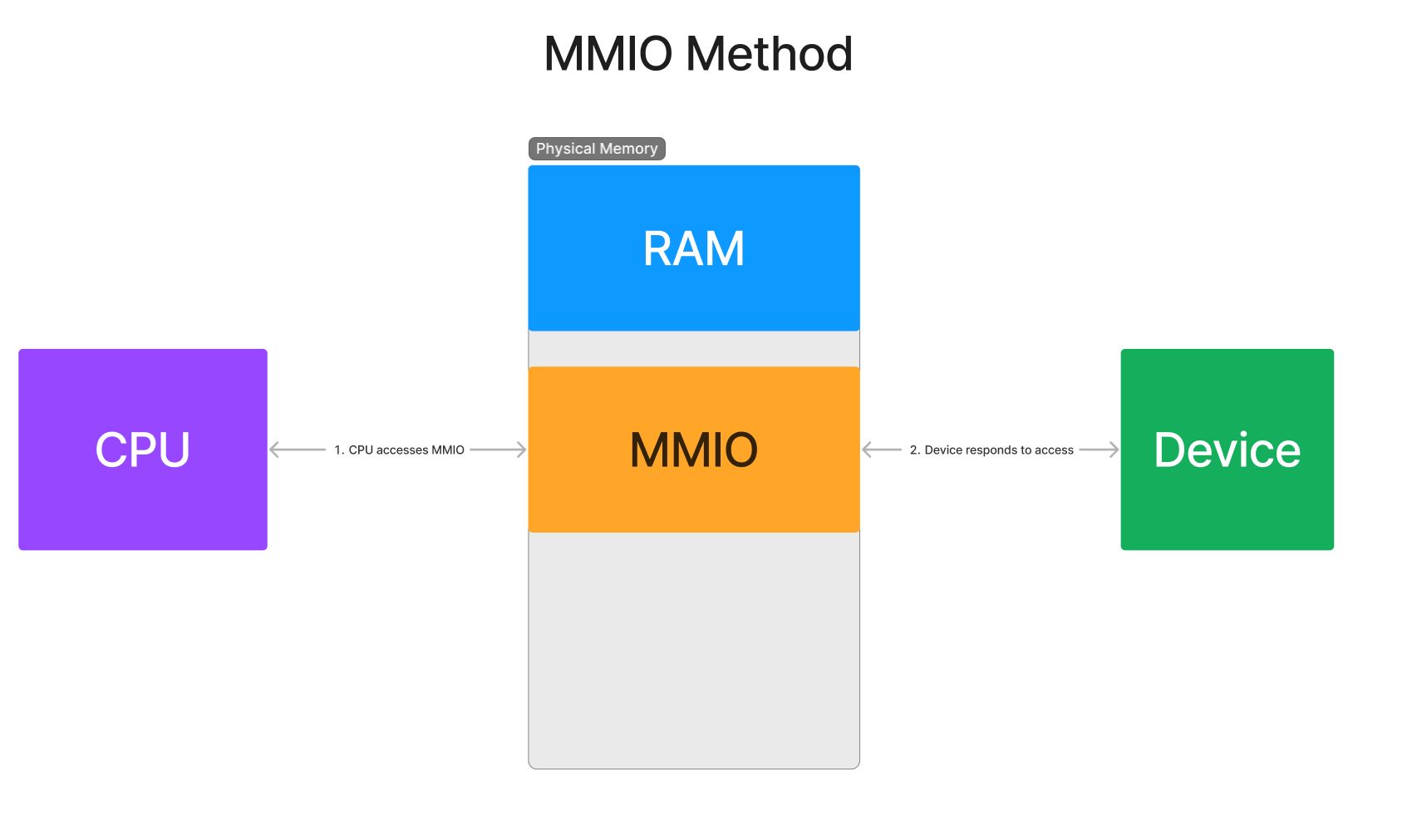
- 内存映射输入/输出(简称 MMIO)- 与主机 CPU 读取和写入内存到 ECAM 以执行配置空间访问类似,MMIO 可以用来映射设备的地址空间,以执行内存传输。主机机器在其物理地址空间中配置“内存窗口”,使 CPU 拥有一个内存地址窗口,这些内存地址神奇地转换为直接读取和写入设备。内存窗口在 RC 中解码,将 CPU 的读取和写入转换为传输到设备的数据 TLPs。硬件优化使得这种方法可以实现比配置空间访问快得多的吞吐量。然而,其速度仍然远远落后于 DMA 的批量传输速度。
- 直接内存访问(简称 DMA)- DMA 是迄今为止最常见的数据传输形式,因为它具有原始传输速度和低延迟。每当驱动程序需要在主机和设备之间沿任一方向进行任何重要大小的传输时,它肯定会是 DMA。但与 MMIO 不同的是,DMA 是由设备本身启动的,而不是由主机 CPU 启动的。主机 CPU 将通过 MMIO 告诉设备 DMA 应该去哪里,设备本身负责开始和完成 DMA 传输。这允许设备在没有 CPU 参与的情况下执行 DMA 事务,与设备必须等待主机 CPU 告诉它每次传输做什么相比,这节省了大量的 CPU 周期。由于 DMA 的普遍性和重要性,从硬件实现和软件层面了解 DMA 非常有价值。

MMIO 简介
什么是 BAR?
由于配置空间限制为 4096 字节,因此之后没有太多可用空间用于特定于设备的功能。如果设备想要映射 1GB 的 MMIO 空间来访问其内部 RAM,该怎么办?没有办法将其放入 4096 字节的配置空间。因此,它将需要请求一个被称为 BAR(基地址寄存器)的东西。这是通过配置空间公开的一个寄存器,允许主机机器配置其内存的一个区域,直接映射到设备上。然后主机机器上的软件通过对 BAR 的物理地址的内存读/写指令来访问 BAR,就像我们在 ECAM 的第一部分中看到的 MMIO 一样。对设备内存映射进行读取或写入的操作将直接转换为发送到层次结构上的设备的数据包。当设备需要响应时,它将通过层次结构向主机机器发送一个新的数据包。
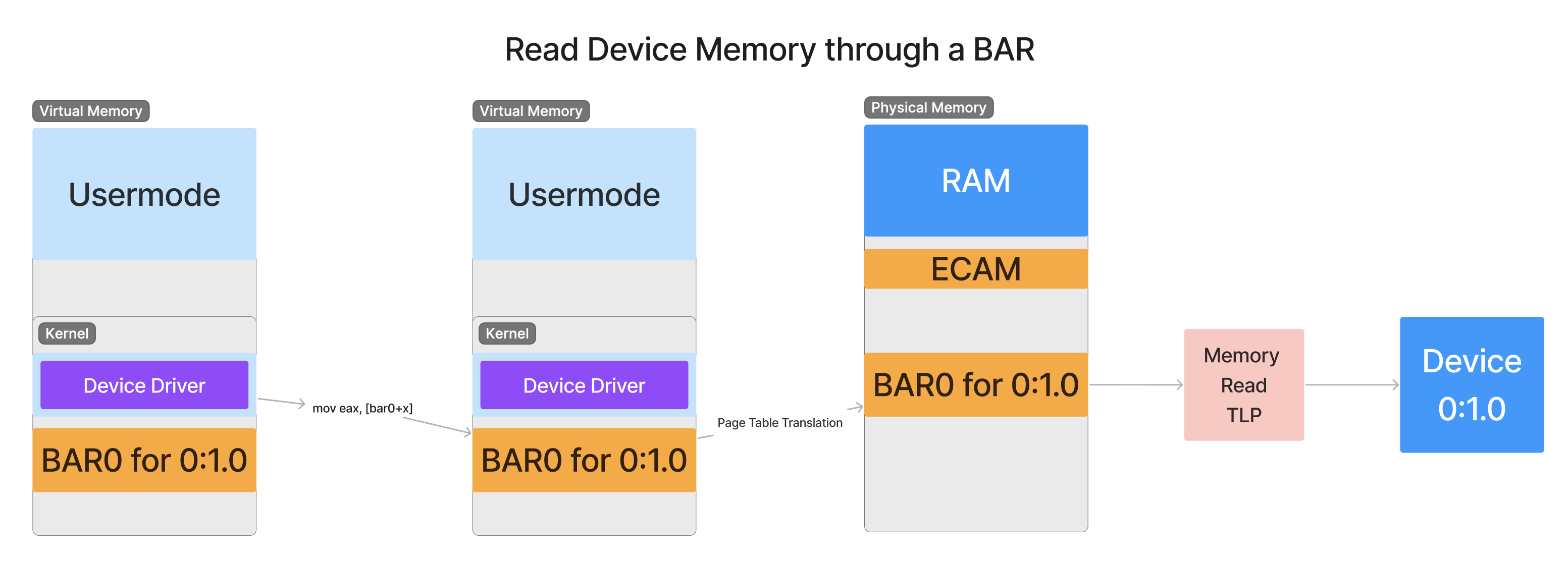
当 CPU 指令读取器件 MMIO 区域的内存时,会生成一个内存读取请求事务层数据包(MemRd TLP),该数据包从主机的 RC 向下传输到器件。这个 TLP 包的目的是通知设备希望读取设备,然后设备需要尽快响应请求地址上的内容。
在 PCIe 中发送和接收的所有数据传输数据包都将采用 TLP 形式。回想一下第 1 部分,这些数据包是设备之间的所有通信都在 PCIe 中发生的中心抽象。这些数据包在出现数据传输错误(类似于网络中的 TCP)的情况下是可靠的,并且可以根据需要重试/重新发送。这确保了数据传输免受 PCIe 可以达到的极高速度下发生的恶劣电气干扰。我们很快就会仔细研究 TLP 的结构,但现在只需将这些视为您在 TCP 中看到的常规网络数据包。
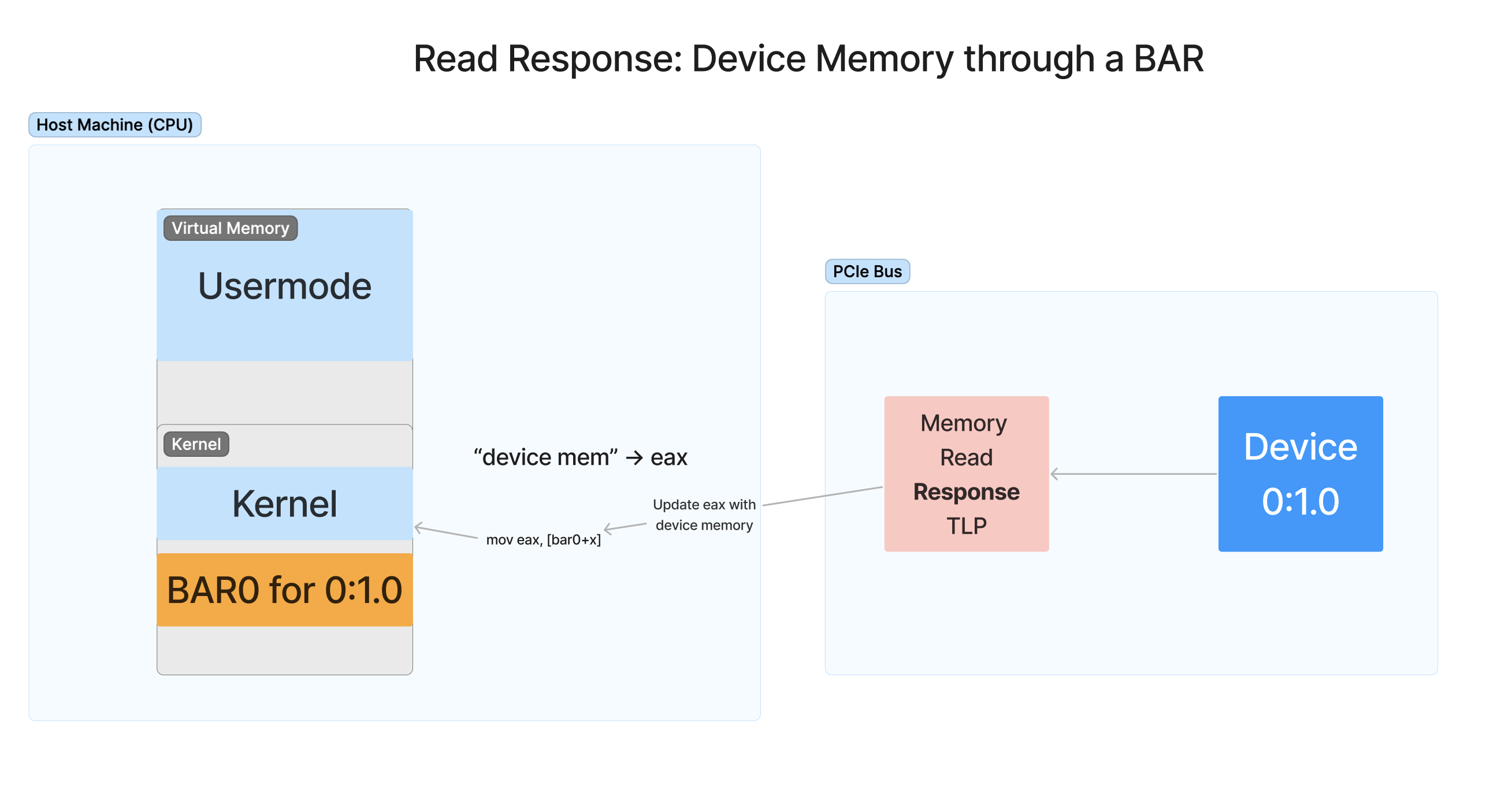
当设备收到请求者数据包时,设备会使用 MemRd TLP 响应内存请求。此 TLP 包含从设备内存空间读取的结果,给定原始请求者数据包中的地址和大小。设备将它正在响应的特定请求数据包和发送方标记到响应数据包中,交换层次结构知道如何将响应数据包返回给请求者。然后,请求者将使用数据包中的数据来更新发起请求的 CPU 寄存器。
同时,当 TLP 正在传输时,CPU 必须等待内存请求完成,并且它不能被中断或执行许多有用的工作。正如你可能看到的,如果需要执行大量这样的请求,CPU 将需要花费大量时间等待设备响应每个请求。虽然在硬件级别进行了优化,使此过程更加简化,但使用 CPU 周期等待数据传输完成仍然不是最佳选择。希望您能看到我们需要第二种类型的传输,即 DMA,来解决 BAR 访问的这些缺点。
这里的另一个重点是,设备内存并不严格需要用于设备的 RAM。虽然通常会看到具有板载 RAM 的设备通过 BAR 公开其内部 RAM 的映射,但这不是必需的。例如,访问设备的 BAR 可能会访问设备的内部寄存器,也可能导致设备执行某些操作。例如,写入 BAR 是设备开始执行 DMA 的主要方式。一个核心要点是,设备 BAR 非常灵活,可用于控制设备或执行与设备之间的数据传输。
如何枚举 BAR?
设备使用其配置空间从软件请求内存区域。在枚举时,由主机确定该区域将放置在物理内存中的位置。每个器件在其配置空间(称为“寄存器”,因此称为基址寄存器)中都有 6 个 32 位值,当枚举器件时,软件将读取和写入这些值。这些寄存器描述了器件希望分配的每个 MMIO 区域的长度和对齐要求,每个可能的 BAR 一个,总共 6 个不同的区域。如果设备希望能够将其 BAR 映射到 4GB 空间(64 位 BAR)以上,它可以将两个 32 位寄存器组合在一起,形成一个 64 位 BAR,最多只留下三个 64 位 BAR。
PCIe
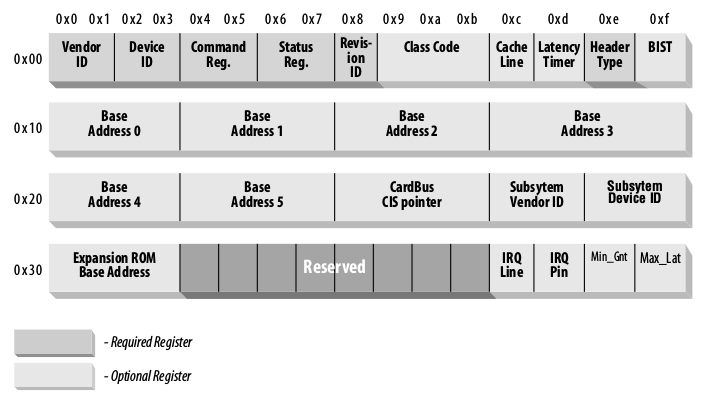
术语注释:尽管首字母缩略词 BAR 表示基址寄存器,但你会看到上面的文本也将 MMIO 的内存窗口称为 BAR。不幸的是,这意味着配置空间中的寄存器名称也与给 device 的 MMIO 区域相同(两者都称为 BAR)。你可能需要根据上下文,以确定它们是指内存窗口,还是配置空间本身的实际寄存器。
BARs 是配置空间中另一个示例,它不是常量寄存器。在第一部分中,我们看了一些常量寄存器,比如 VendorID 和 DeviceID。但是 BARs 不是常量寄存器,它们应该由软件写入和读取。实际上,由软件写入寄存器的值是特殊的,因为将某些类型的值写入寄存器将导致读取时功能不同。如果你没有牢记设备内存并非总是 RAM,读取回来的值可能与写入的不同,那么现在正是时候这么做了。
设备内存可以是 RAM,但它并不总是 RAM,也不需要像 RAM 那样工作!
什么是 DMA?引言和理论
到目前为止,我们已经看到了两种形式的 I/O,配置空间访问和通过 BAR 的 MMIO 访问。我们将讨论的最后一种也是最后一种访问形式是直接内存访问(DMA)。DMA 是迄今为止最快的 PCIe 批量传输方法,因为它的传输开销最小。也就是说,通过链路传输最大字节数所需的资源最少。这使得 DMA 对于真正利用 PCIe 提供的高速链路至关重要。
但是,强大的力量会带来巨大的混乱。对于软件开发人员来说,DMA 是一个非常陌生的概念,因为我们在软件中没有类似的东西可以比较。对于 MMIO,我们可以将内存访问概念化为从设备内存中读取和写入的指令。但 DMA 与此非常不同。这是因为 DMA 是异步的,它不利用 CPU 来执行传输。相反,顾名思义,读取和写入的内存直接来自系统 RAM。一旦 DMA 开始,唯一涉及的各方是系统主内存的内存控制器和设备本身。因此,CPU 不会花费周期等待单个内存访问。相反,它只是启动转移,并让平台在后台自行完成 DMA。然后,平台将在传输完成时通知 CPU,通常是通过中断。
让我们想一想,为什么异步执行 DMA 如此重要。考虑 CPU 从计算机上的 NVMe SSD 解密大量文件的情况。一旦主机上的 NVMe 驱动程序启动 DMA,设备就会不断以最快的速度将文件数据从 SSD 的内部存储传输到 CPU 可以访问的系统 RAM 中的位置。然后,CPU 可以使用其 100% 的处理能力来执行解密数学运算,以便在从系统内存中读取数据时解密文件块。CPU 不会花时间等待对设备进行单个内存读取,而是简单地连接数据,并允许设备尽可能快地传输,而 CPU 会尽可能快地处理它。在此期间,任何额外的数据都会在系统 RAM 中缓冲,直到 CPU 可以访问它。这样,任何过程的任何部分都不会等待其他事情发生。所有这些都以尽可能快的速度同时发生。
由于 DMA 的复杂性和涉及的部件数量,我将尝试以最直接的方式解释 DMA,并用大量图表来显示该过程。更令人困惑的是,每个设备都有不同的 DMA 接口。没有用于执行 DMA 的通用软件接口,只有器件的设计人员知道如何告诉该器件执行 DMA。值得庆幸的是,某些设备类别使用普遍认可的接口,例如大多数 SSD 使用的 NVMe 接口或 USB 3.0 的 XHCI 接口。如果没有标准接口,则只有硬件设计人员知道设备如何执行 DMA,因此生产设备的公司或个人需要是编写设备驱动程序的人,而不是依赖与操作系统捆绑的通用驱动程序与设备通信。
一个简单的 DMA 传输 - Step by Step
我们 DMA 旅程的第一步是查看传输的初始设置。这涉及几个步骤,为即将到来的 DMA 传输准备系统内存、内核和设备。在这种情况下,我们将设置 DMA,以便读取系统 RAM 中存在的 DMA 缓冲区中的内存内容,并将其放入 Target Memory 的器件板载 RAM 中。此时我们已经选择将此内存从 DMA Buffer 读取到器件上地址为 0x8000 中。目标是尽快将此内存从系统内存传输到设备,以便它可以开始处理它。假设在这种情况下,内存量几 M 字节,MMIO 会太慢,但为简单起见,我们将仅显示 32 字节的内存。这种传输将是最简单的 DMA 传输类型:将内存块的已知大小和地址从系统 RAM 复制到设备 RAM。
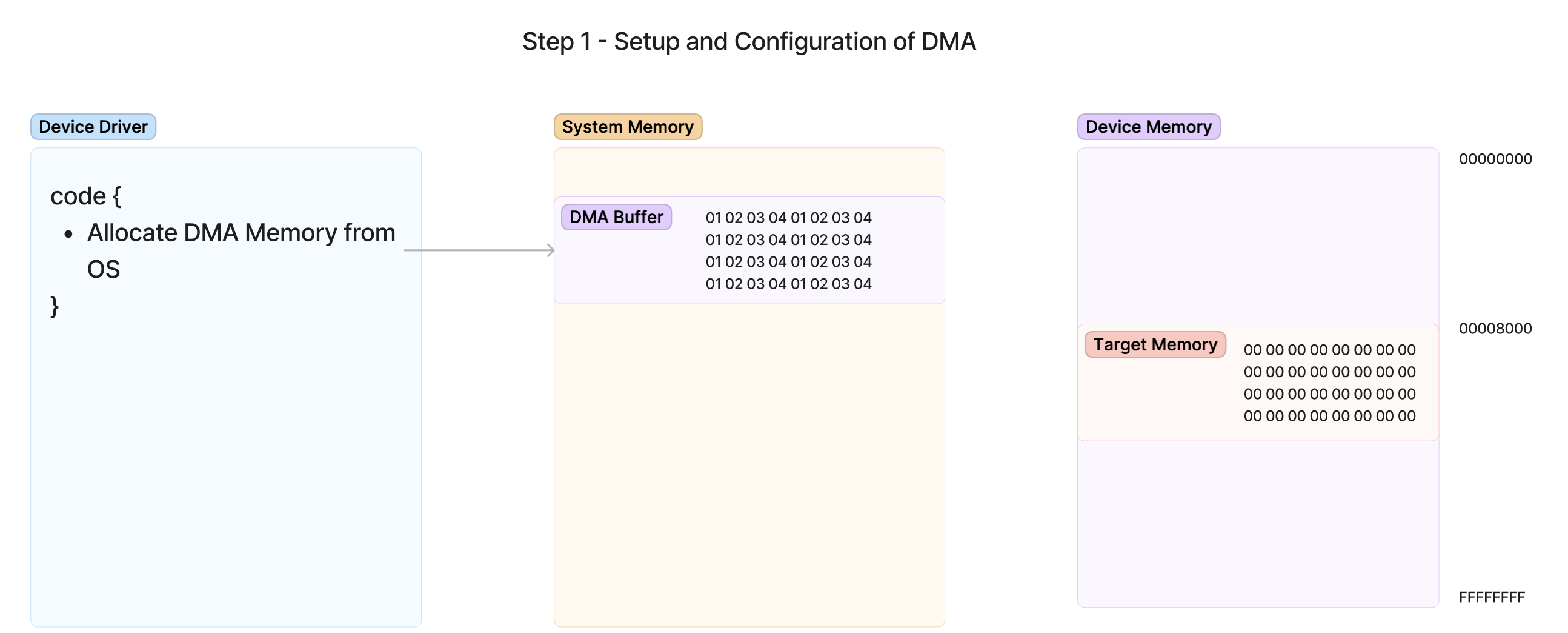
第 1 步 - 从操作系统分配 DMA 内存
此过程的第一步是从 OS 分配 DMA 内存。这意味着设备驱动程序必须进行 OS API 调用,以请求 OS 为设备分配一个内存区域以将数据写入。这一点很重要,因为操作系统可能需要执行特殊的内存管理操作才能使数据对设备可用,例如删除保护或重新组织现有分配以促进请求。
传统上,DMA(直接内存访问)存储器必须是连续的物理存储器,这意味着设备从某个地址和长度的起始处开始,并线性地从缓冲区的起始位置读取/写入数据直到结束。因此,操作系统必须负责组织其物理内存,以创建足够大的连续范围,以满足驱动程序请求的 DMA 缓冲区。有时,对于长时间运行或物理内存有限的系统来说,这可能非常困难。因此,这一领域的增强功能允许更现代的设备使用 Scatter-Gather 和 IOMMU Remapping 等功能传输到非连续的存储器区域。稍后,我们将看一些这些功能。但现在,我们只专注于更简单的连续内存情况。
一旦请求的分配成功,API 将返回内存地址,并指向系统 RAM 中的缓冲区。这将是设备通过 DMA 访问内存的地址。DMA 意图为 API 返回的地址将被赋予一个特殊的名称; 设备逻辑地址或逻辑地址。对于我们的示例,逻辑地址等同于物理地址。设备看到的是操作系统看到的物理内存的完全相同视图,没有额外的转换。然而,在更高级的传输形式中,情况可能并非总是如此。因此最好意识到,设备给出的地址可能并非总是与其在 RAM 中实际的物理地址相同。
分配缓冲区后,由于目的是将数据从此缓冲区移动到设备,因此设备驱动程序将提前使用写入设备所需的信息填充缓冲区。在此示例中,由重复 01 02 03 04 模式组成的数据正在传输到设备的 RAM。
第 2 步 - 将 DMA 地址写入设备并开始传输
传输的下一步是准备设备执行事务所需的信息。这通常是了解器件的特定 DMA 接口最重要的地方。每个设备都以自己的方式进行编程,了解驱动程序应该如何对设备进行编程的唯一方法是参考其通用标准(如 NVMe 规范)或简单地与硬件设计人员合作。
在这个例子中,我将为一个只有执行传输所需的最基本功能的设备构建一个简化的 DMA 接口。在下面的图表中,我们可以看到这个设备通过向 BAR0 MMIO 区域写入数值来进行编程。这意味着为了为这个设备编程 DMA,驱动程序必须将内存写入由 BAR0 指定的 MMIO 区域。每个寄存器在 BAR0 区域内的位置是由驱动程序编写者提前知道的,并且被集成到设备驱动程序的代码中。
对于此示例、我在 BAR0 中创建了四个器件寄存器:
- Destination Address(目标地址) - 设备内部 RAM 中用于写入从系统 RAM 读取的数据的地址。这是我们将对已经确定的目标地址 0x8000 进行编程的地方。
- Source Address(源地址) - 设备将从中读取数据的系统 RAM 的逻辑地址。这将对我们希望设备读取的 DMA Buffer 的逻辑地址进行编程。
- Transfer Size(传输大小) - 我们要传输的大小(以字节为单位)。
- Initiate Transfer(启动传输标志位)- 一旦次寄存器写入 1,器件将开始在上面给出的地址之间进行传输。通过这种方式,驱动程序可以判断设备已完成填充缓冲区并准备好开始传输。这通常被称为门铃(Door Bell)寄存器。
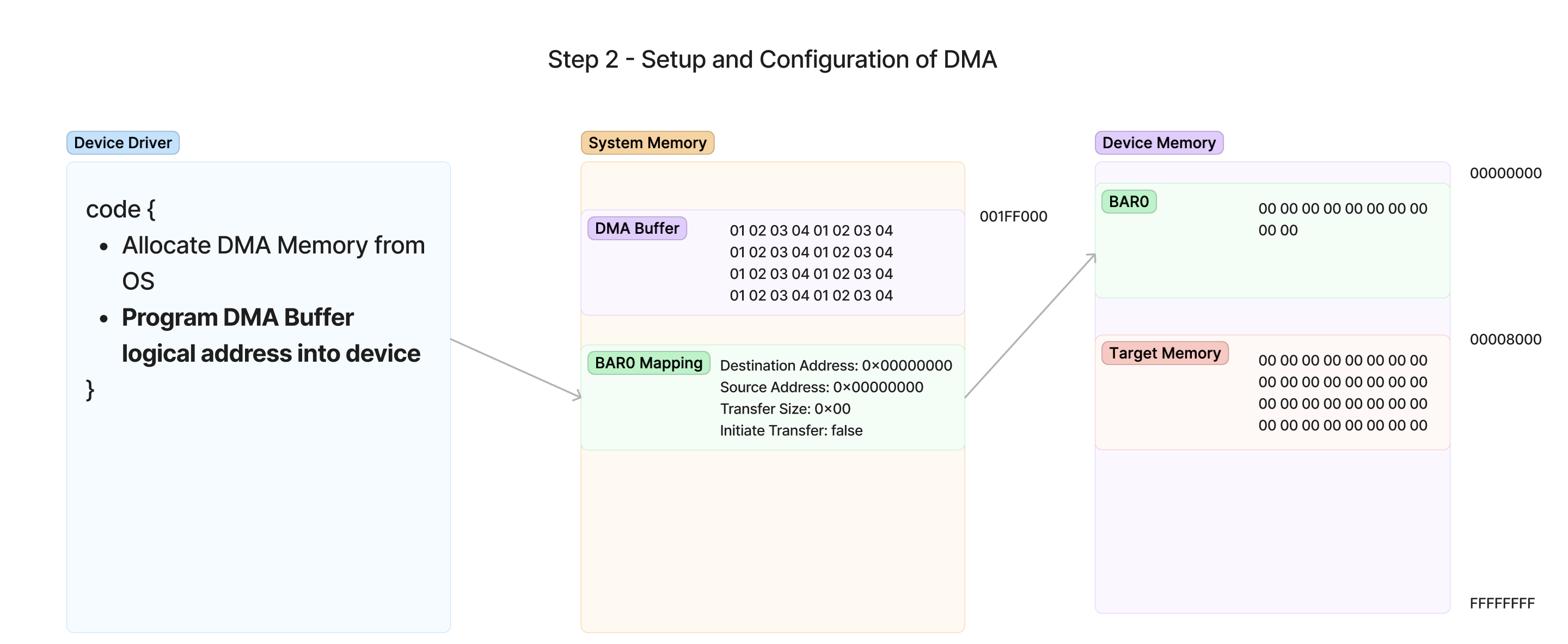
在上图中,驱动程序需要使用器件的 BAR0 的映射内存将必要的值写入寄存器(它如何映射此内存取决于 OS)。此图中的值如下所示:
- Target Memory - 我们要从器件复制的内存将为
0x00008000,它映射到器件板载 RAM 中的内存区域。这将是我们的目标地址。 - DMA 缓冲区 - 操作系统在
0x001FF000分配内存块,因此这将是我们的源地址。
有了这些信息,驱动程序现在可以将值编程到设备中,如下所示:
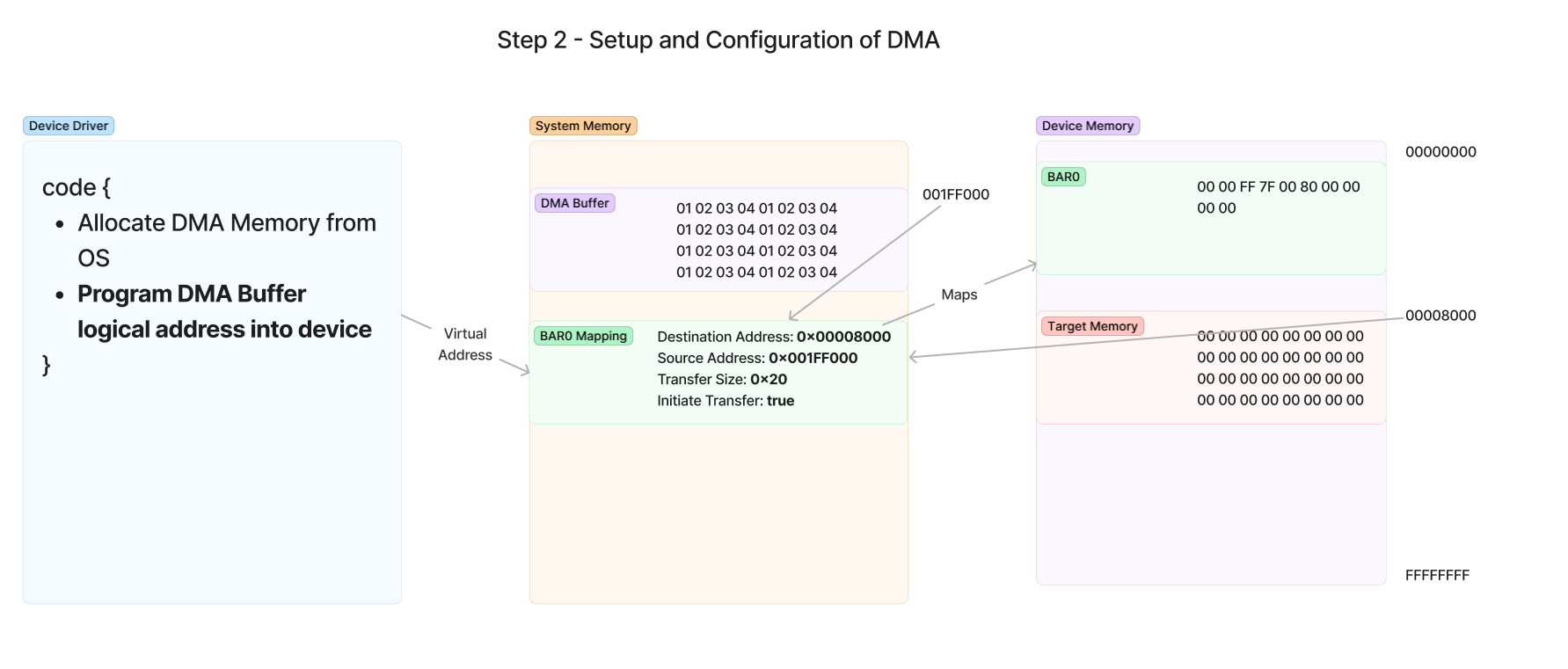
现在,驱动程序已经配置了执行传输所需的所有寄存器。最后一步是向启动传输寄存器写入一个值,该寄存器充当开始传输的 Door bell 寄存器。一旦写入此值,设备将驱动 DMA 传输,并独立于驱动程序或 CPU 的参与执行它。驱动程序已完成启动传输的工作,此时 CPU 可在等待设备通知系统 DMA 完成的同时,自由进行其他工作。
第 3 步 - 设备执行 DMA 事务
现在,驱动程序已写入 Door bell 寄存器,设备现在将接管处理实际传输。在设备本身上,存在一个名为 DMA 引擎的模块,负责处理和维护事务的所有方面。当器件被编程时,对 BAR0 的寄存器写入正在对 DMA 引擎进行编程,其中包含开始在 PCIe 链路上发送必要的 TLP 以执行内存事务所需的信息。
如上一节所述,PCIe 链路上的所有内存操作都是通过 Memory Write/Read TLP 完成的。在这里,我们将深入研究在交易发生时设备的 DMA 引擎发送和接收的 TLP。请记住,更容易将 TLP 视为在单个可靠连接上发送和接收数据的网络数据包。
如在前文部分讨论过的,PCIe 链接上的所有内存操作都是通过内存写入/读取 TLPs 来完成的。在这里,我们将深入探讨设备的 DMA 引擎在传输过程中发送和接收的 TLPs。要牢记的是,将 TLPs 视为在一个单一、可靠的连接上发送和接收数据的网络数据包更易于理解。
插曲:快速了解 TLP
在查看链路上的 TLP 之前,让我们仔细了解一下数据包结构本身的概览。
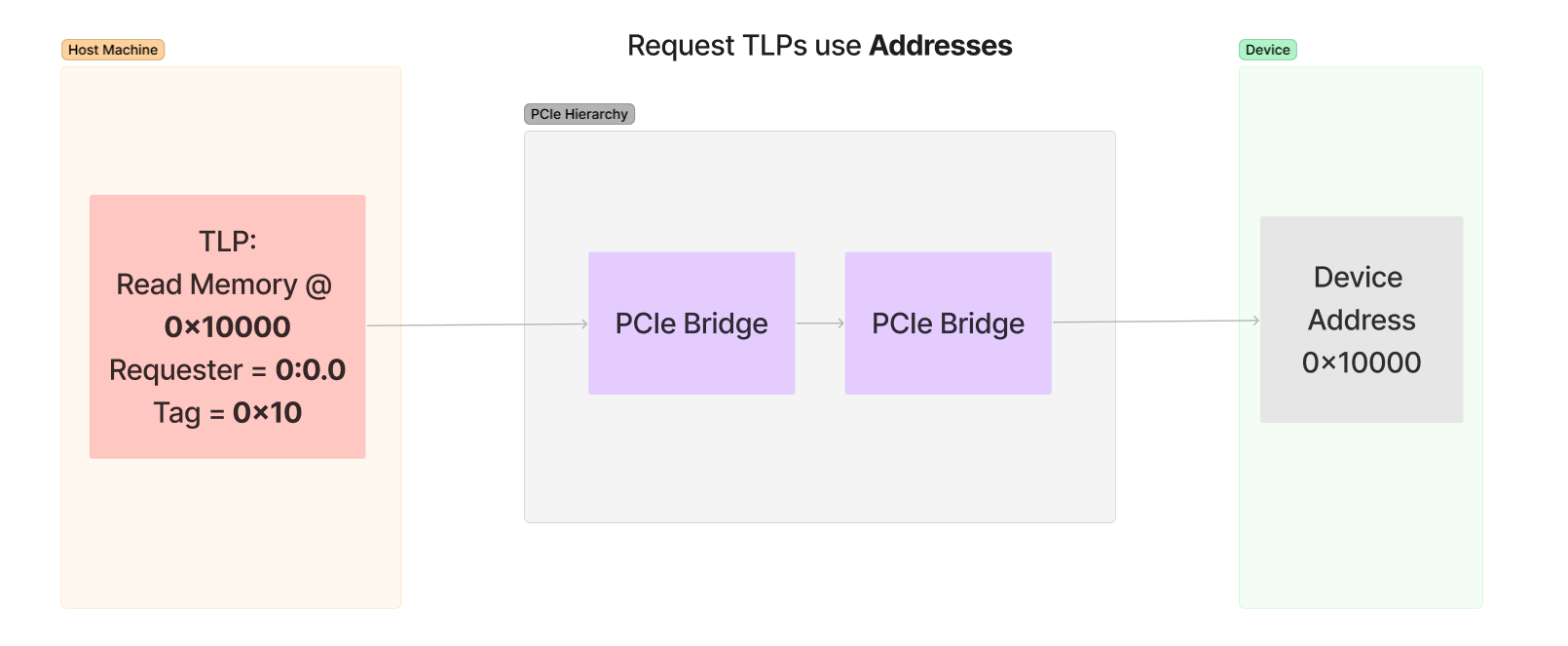
以下是内存读取请求和响应的两个 TLP。如前所述,用于内存操作的 TLP 利用请求和响应系统。执行读取的设备将生成特定地址和长度(以 4 字节 DWORD 为单位)的读取请求 TLP,然后坐下来等待完成数据包到达包含响应数据的链路。
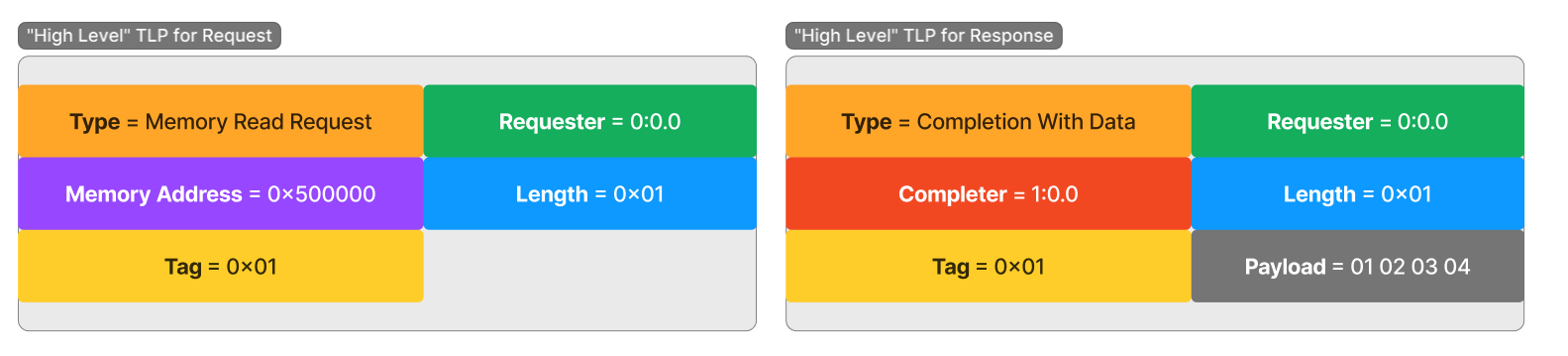
我们可以看到,有与生成请求的设备、Requester 以及唯一的 Tag 值相关的元数据。此 Tag 值用于将请求与其完成匹配。当设备生成请求时,它会使用唯一值标记 TLP 以跟踪待处理的请求。该值由请求的发送者选择,并且由发送者来跟踪其分配的 Tags。
随着完成的数据通过链路到达,完成的 Tag 让设备能够将接入的数据正确地移至特定传输所需的位置。该系统允许单一设备有多个独特的未完成传输任务,尽管它们接收的数据包相互交错,但仍能保持作为独立传输任务的有序性。
数据包内部还包含了必要的信息,使得 PCIe 切换层次结构能够确定请求和完成需要去向的位置。例如,内存地址被用来确定正在请求访问的设备是哪一个。在枚举期间,层次结构中的每一个设备都被编程以拥有各自独特的地址范围。切换结构根据数据包中的内存地址,确定数据包需要去向哪里以访问那个地址。
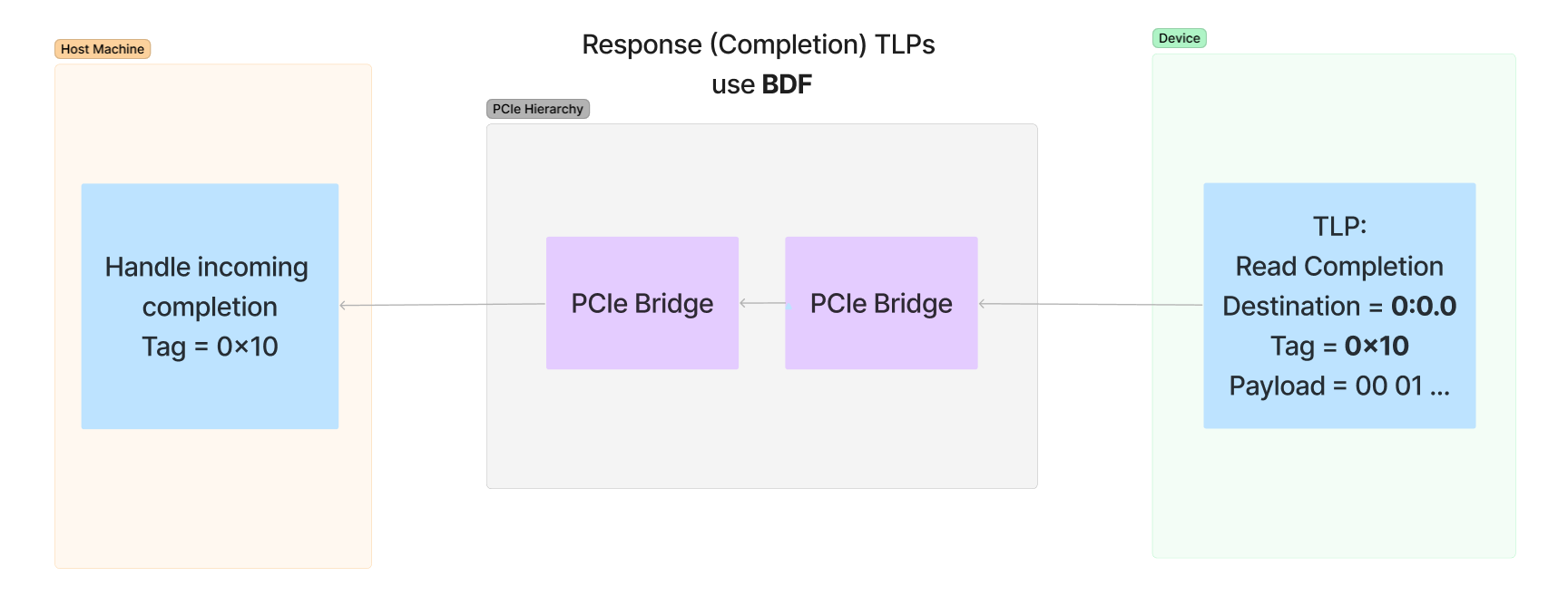
设备收到并处理请求后,响应数据将以 Completion TLP 的形式发送回去。完成或“响应”数据包可以而且通常会被分段为许多较小的 TLP,这些 TLP 发送整体响应的一部分。这是因为在枚举期间,已确定设备和总线可以处理最大有效载荷大小(MPS)。MPS 可根据平台和设备功能进行配置,从 128 开始,最高可达 4096 的 2 次方大小。通常,此值约为 256 字节,这意味着需要将大型读取请求拆分为许多较小的 TLP。这些数据包中的每一个都有一个字段,该字段指示完成响应的原始请求的偏移量,有效负载中是返回的数据块。
有一个常见的误解,即内存 TLP 使用 BDF 来寻址数据包需要去往的位置。其实请求仅使用内存地址来指示数据包的目的地,并且设备和目标之间的桥接设备负责将该数据包发送到其正确的位置。。然而,完成数据包确实利用请求者的 BDF 将数据返回给发起请求的设备。
以下是一个展示内存读取和响应过程的图表,图中展示出请求会使用一个地址来发起请求,而完成的操作会使用请求中 Request 字段的 BDF 来发送相应应答:
现在回到实际的传输
让我们看看 DMA 引擎为了执行我们的请求而发送和接收的所有内容。由于我们请求了 32 字节的数据,因此只有一个单一的 Memory Read Request 和一个带有响应的单一 Memory Read Completion 数据包。为了便于您理解,请停止向前阅读,并考虑一下在此事务中哪个设备将发送和接收哪个 TLP。如果您需要再次查看第 2 步的图表,请向上滚动。
现在,让我们深入研究一下传输的实际数据包。虽然我将继续绘制这个模拟示例,但我认为对于这个练习,当执行真实传输时,实际看到其中一些 TLP 是什么样子可能会很有趣。
在实验中,我使用真实设备配置了如上文所示的同类通用参数,并启动了 DMA。这个设备会发送真实的 TLPs,将系统 RAM 中的内存读取到设备里。因此,你将有机会罕见地查看在执行这种 DMA 时发送的实际 TLPs 的例子,除非有分析器,否则这些在传输过程中几乎无法看到。
要查看此实验,请点击此链接至配套文章:Experiment - Packet Dumping PCIe DMA TLPs with a Protocol Analyzer and Pcileech – Reversing Engineering for the Soul
以下是器件生成的内存读取请求以及请求如何遍历层次结构的框图。
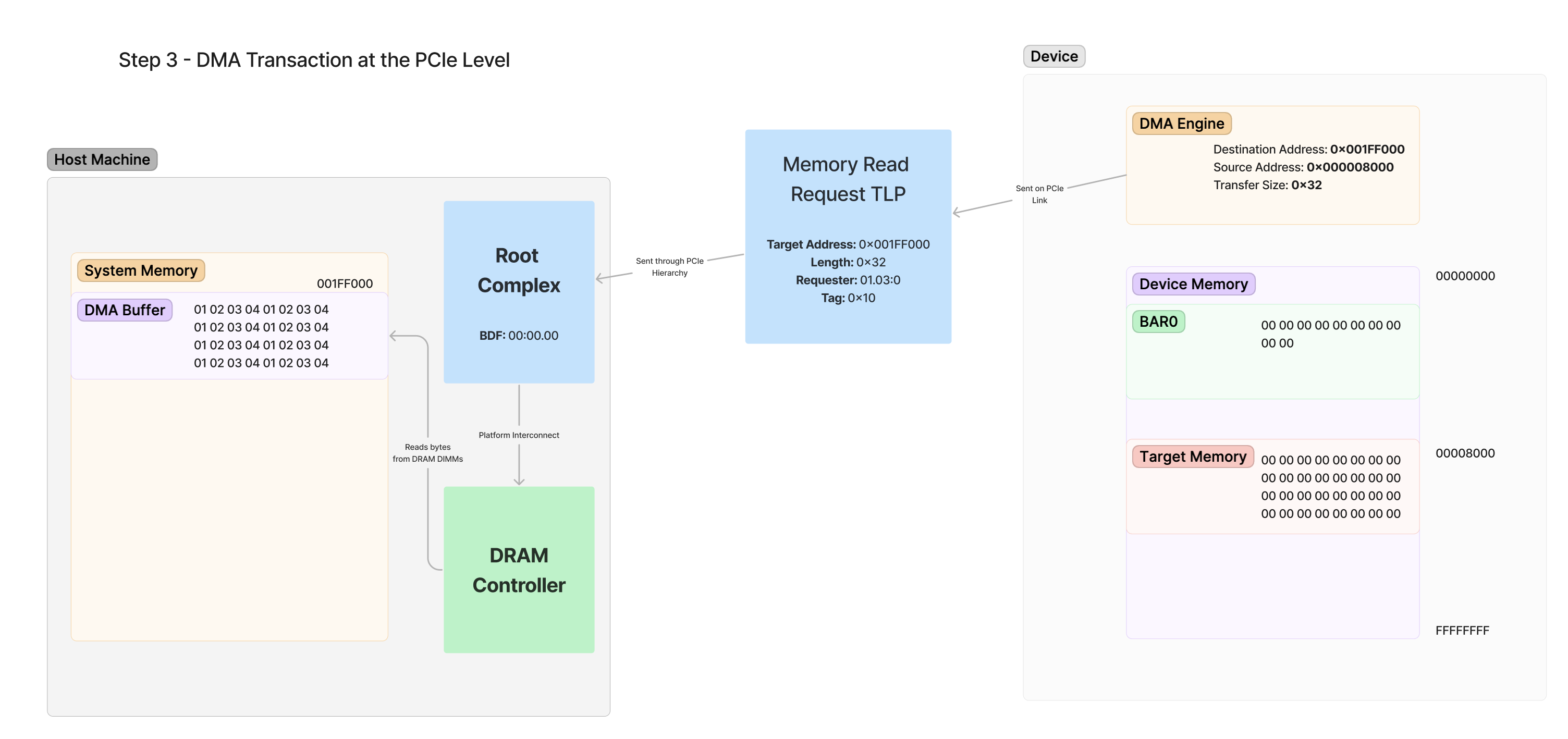
勘误表:0x32 应该是 32
此图中概述的步骤如下:
- DMA 引擎创建 TLP - DMA 引擎识别出它必须从 0x001FF000 读取 32 字节。它生成一个包含此请求的 TLP,并通过其本地 PCIe 链路将其发送出去。
- TLP 遍历层次结构 - PCIe 的交换层次结构通过桥接设备移动此请求,直到它到达其目的地,即 RC。回想一下,RC 负责处理所有用于访问系统 RAM 的传入数据包。
- 通知 DRAM 控制器 - RC 在内部与 DRAM 控制器通信,该控制器负责实际访问系统 DRAM 的内存。
- 从 DRAM 读取内存 - 从地址 0x001FF000 的 DRAM 请求给定长度的 32 字节,并将其返回到值为 01 02 03 04…
尽量不要被这些信息淹没,因为我确实知道仅针对单个内存请求 TLP 就有很多事情要做。所有这些在高层次上归结为仅从 RAM 中的地址 0x001FF000 读取 32 字节的内存。平台如何通过与 DRAM 控制器通信来实际读取系统 DRAM,仅供您参考。设备本身不知道 Root Complex 实际上是如何读取此内存的,它只是使用 TLP 启动传输。
注意:此处未显示更复杂的 RAM 缓存过程。在 x86-64 上,来自设备的所有内存访问都是缓存一致的,这意味着平台会自动将 CPU 缓存与设备正在访问的值同步。在其他平台(如 ARM 平台)上,由于其缓存架构,这是一个更复杂的过程。现在,我们只假设缓存一致性正在自动为我们处理,我们对此没有任何特别的担忧。
当 RC 收到此 TLP 时,它会在内部标记 Requester 和 Tag 的读取内容。当它等待 DRAM 响应该值时,此请求的信息将在 RC 中等待。要概念化这一点,可以将其视为网络套接字中的“open connection”。RC 知道它需要响应什么,因此会等到响应数据可用后,再通过套接字将数据发送回去。
最后,将 Completion 从 Root Complex 发送回设备。请注意,Destination 与 Requester 相同:
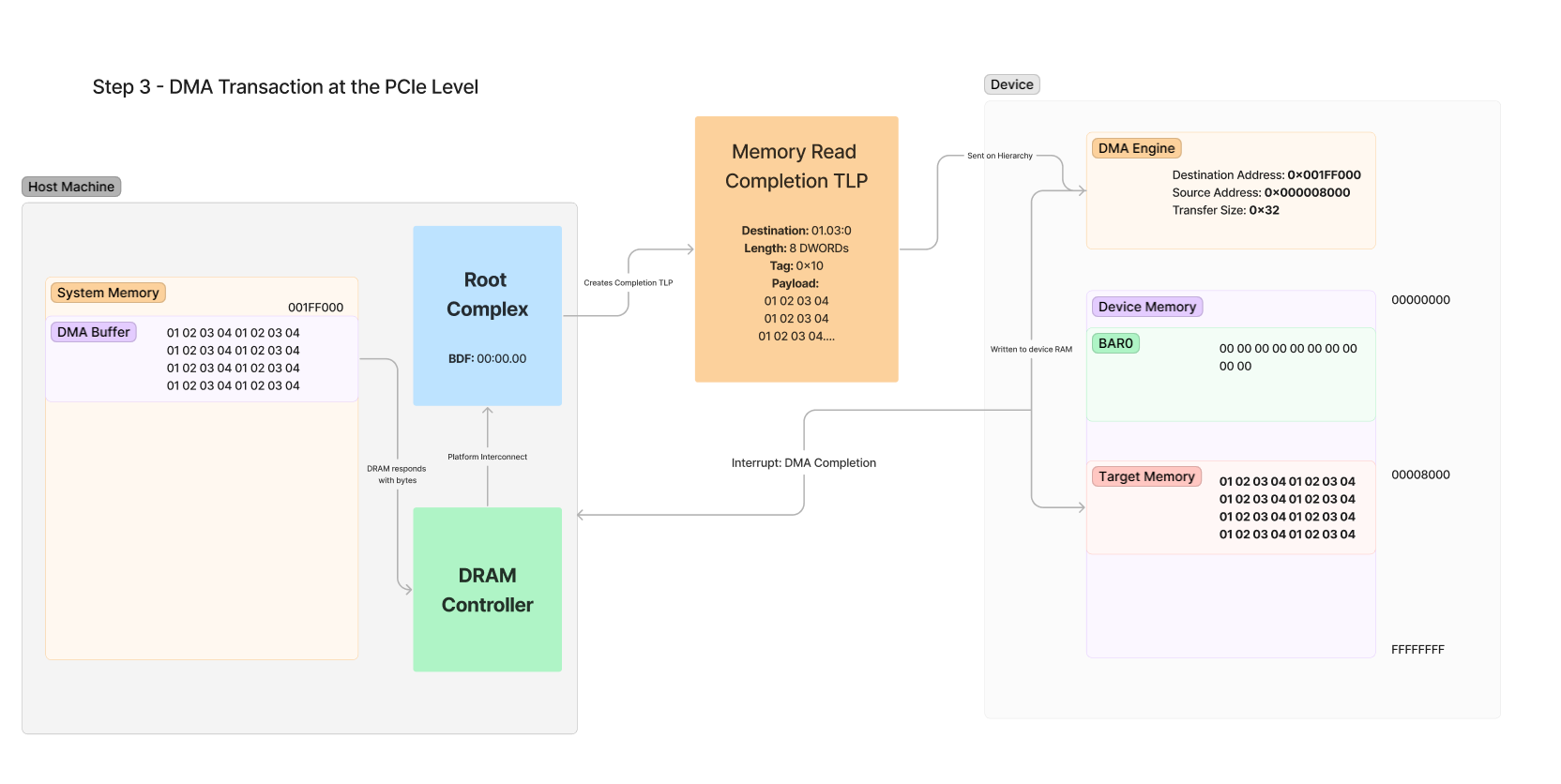
以下是响应数据包概述的步骤,如上所示:
- 从 DRAM 读取内存 - DRAM 控制器从系统 DRAM 中 0x001FF000 的 DMA 缓冲区地址读取 32 字节。
- DRAM 控制器响应根复合体 - DRAM 控制器在内部响应从 DRAM 向 RC 请求的内存
- RC 生成完成 - RC 跟踪传输并为从 DRAM 读取的值创建完成 TLP。在此 TLP 中,元数据值是根据 RC 对待处理传输的了解来设置的,例如发送的字节数、传输的标记以及从原始请求的 Requester 字段复制的目标 BDF。
- DMA 引擎接收 TLP - DMA 引擎通过 PCIe 链路接收 TLP,并查看标签是否与原始请求的相同标签匹配。它还会在内部跟踪此值,并知道有效负载中的内存应写入 Target Memory,该内存在设备内部 RAM 中处于 0x8000。
- Target Memory is Written(目标内存已写入) - 设备内存中的值将更新为从数据包的 Payload 中复制的值。
- 系统中断 - 虽然这是可选的,但大多数 DMA 引擎将配置为在 DMA 完成时中断主机 CPU。这会在设备成功完成 DMA 时向设备驱动程序发出通知。
同样,仅处理这个 complete 数据包就涉及很多步骤。但是,同样,您可以将整个过程简单地视为“从设备的请求中收到 32 字节的响应”。这些步骤的其余部分只是为了向您展示此响应处理的完整端到端是什么样子。
从这里,设备驱动程序会收到 DMA 已完成的通知,设备驱动程序的代码负责清理 DMA 缓冲区或将其存储起来以供下次使用。
在我们的艰苦努力后,我们终于完成了一次单一的 DMA 传输事务!想到这就是我能提供的最“简单”的传输方式,真是让人惊讶。有了 IOMMU 重映射和 Scatter-Gather 能力的加入,这些事务甚至可能变得更复杂。但就现在而言,你应该对 DMA 的全部内容以及它如何在真实设备中运作有了深入的理解。
尾声 - 关于复杂性的小说明
如果您读完这篇文章并觉得自己没有完全掌握所有抛给您的概念,或者对复杂性感到不知所措,您不必担心。这些帖子如此复杂的原因是它不仅涵盖广泛的主题,而且还涵盖广泛的专业。通常,整个系统的每个部分在行业中都有不同的团队,他们只关注他们在这个复杂机器中的“齿轮”。通常,硬件开发人员专注于设备,驱动程序开发人员专注于驱动程序代码,而操作系统开发人员专注于资源管理。这些团队之间很少有太多重叠,除非在他们的边界交接,以便另一支团队可以连接到它。
这些帖子有点独特,因为它们试图将系统作为一个整体进行记录,以便于概念理解,而不是实现。这意味着,在通常划定团队边界的地方,这些帖子根本不关心。我鼓励觉得这个话题有趣的读者在自己的时间里继续深入研究。也许您可以了解一些 FPGA 并开始制作自己的设备,或者您可以购买一个设备并开始尝试对其进行逆向工程,并通过您自己的定制软件与它进行通信。
总结
希望您喜欢这篇深入探讨 PCIe 内存传输的文章!虽然我在这篇文章中涵盖了大量信息,但兔子洞总是更深。值得庆幸的是,通过学习配置空间访问、MMIO(BAR)和 DMA,您现在已经涵盖了 PCIe 中可用的各种形式的数据通信!对于连接到 PCIe 总线的每个设备,主机系统和设备之间的通信将通过这三种方法中的一种进行。设备的链接、资源和驱动程序软件的所有设置和配置最终都是为了促进这三种形式的通信。
这篇文章花了这么长时间才发布的一个重要原因是,为了理解这一切,我必须向读者展示大量信息。很难决定什么值得写,什么太深以至于理解变得模糊。这个决定瘫痪使博客写作过程花费的时间比我预期的要长得多。再加上全职工作,很难找到时间来撰写这些帖子。
在即将发布的帖子中,我期待着讨论以下一些或所有的话题:
- 层次结构的 PCIe 交换/桥接和枚举
- 更高级的 DMA 主题,例如 DMA 重新映射
- 电源管理;设备如何“睡眠”和“唤醒”
- 平台/OS 的中断及其分配和处理
- 设备的简单驱动程序开发示例
与往常一样,如果你有任何问题或想评论或讨论这个系列的某个方面,你最好在我的 discord 的 #hardware 频道中通过“@gbps”找到我,逆向工程 discord
请期待未来的帖子!