存储器
存储器的层次结构
SRAM(Static Random-Access Memory,静态随机存取存储器)
CPU 如果形容成人的大脑的话,那么 CPU Cache (高速缓存) 就好比人的记忆。它用的是 SRAM 芯片。
SRAM 的“静态”的意思是,只要处于通电状态,里面的数据就保持存在,一旦断电,数据就会丢失。SRAM 里 1bit 数据需要 6-8 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间,能够存的数据有限。因为其电路简单,访问速度非常快。
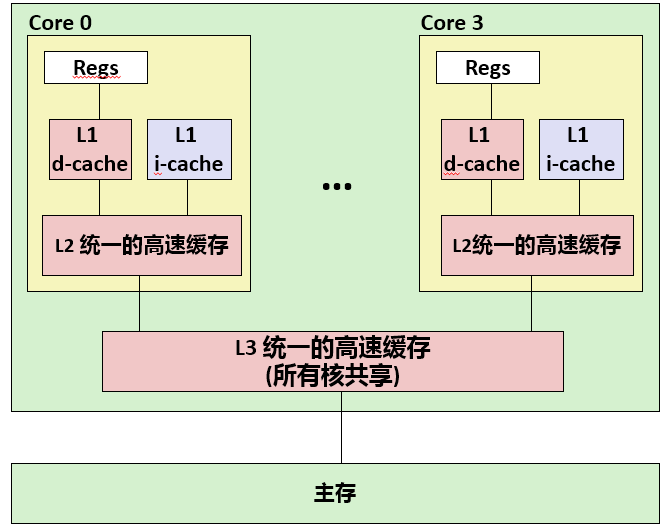
在 CPU 里,通常会有 L1、L2、L3 这样三层高速缓存。每个 CPU 核心都有一块属于自己的 L1 高速缓存,通常分成指令缓存和数据缓存,分开存放 CPU 使用的指令和数据。
L2 的 Cache 同样是每个 CPU 核心都有的,不过它往往不在 CPU 核心的内部。所以,L2 Cache 的访问速度会比 L1 稍微慢一些。而 L3Cache,则通常是多个 CPU 核心共用的,尺寸会更大一些,访问速度自然也就更慢一些。
你可以把 CPU 中的 L1Cache 理解为我们的短期记忆,把 L2/L3Cache 理解成长期记忆,把内存当成我们拥有的书架或者书桌。当我们自己记忆中没有资料的时候,可以从书桌或者书架上拿书来翻阅。这个过程中就相当于,数据从内存中加载到 CPU 的寄存器和 Cache 中,然后通过“大脑”,也就是 CPU,进行处理和运算。
DRAM(Dynamic Random Access Memory,动态随机存取存储器)
内存用的芯片和 Cache 有所不同,它用的是一种叫作 DRAM 的芯片,比起 SRAM 来说,它的密度更高,有更大的容量,而且它也比 SRAM 芯片便宜不少。
DRAM 被称为“动态”存储器,是因为 DRAM 需要靠不断地“刷新”,才能保持数据被存储起来。DRAM 的一个比特,只需要一个晶体管和一个电容就能存储。所以,DRAM 在同样的物理空间下,能够存储的数据也就更多,也就是存储的“密度”更大。但是,因为数据是存储在电容里的,电容会不断漏电,所以需要定时刷新充电,才能保持数据不丢失。DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问延时也就更长。
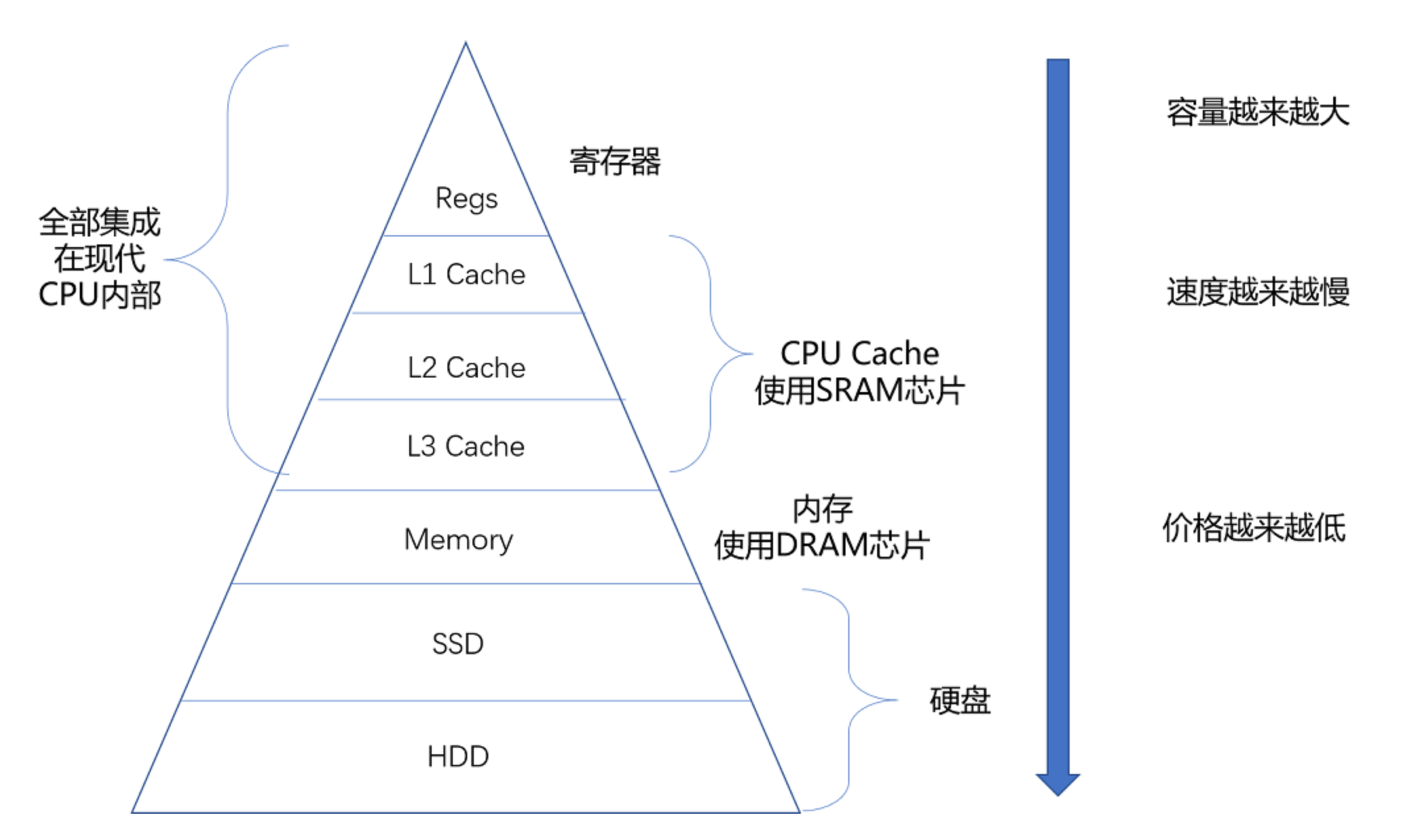
从 Cache、内存,到 SSD 和 HDD 硬盘,一台现代计算机中,就用上了所有这些存储器设备。其中,容量越小的设备速度越快,而且,CPU 并不是直接和每一种存储器设备打交道,而是每一种存储器设备,只和它相邻的存储设备打交道。比如,CPUCache 是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到 CPUCache 中,而是先加载到内存,再从内存加载到 Cache 中。
这样,各个存储器只和相邻的一层存储器打交道,并且随着一层层向下,存储器的容量逐层增大,访问速度逐层变慢,而单位存储成本也逐层下降,也就构成了我们日常所说的存储器层次结构。
缓存
CPU cache
高速缓存
缓存不是 CPU 的专属功能,可以把它当成一种策略,任何时候想要增加数据传输性能,都可以通过加一层缓存试试。
存储器层次结构的中心思想是,对于每个$k$,位于$k$层的更快更小的存储设备作为位于$k+1$层的更大更慢的存储设备的缓存。下图展示了存储器层次结构中缓存的一般性概念。
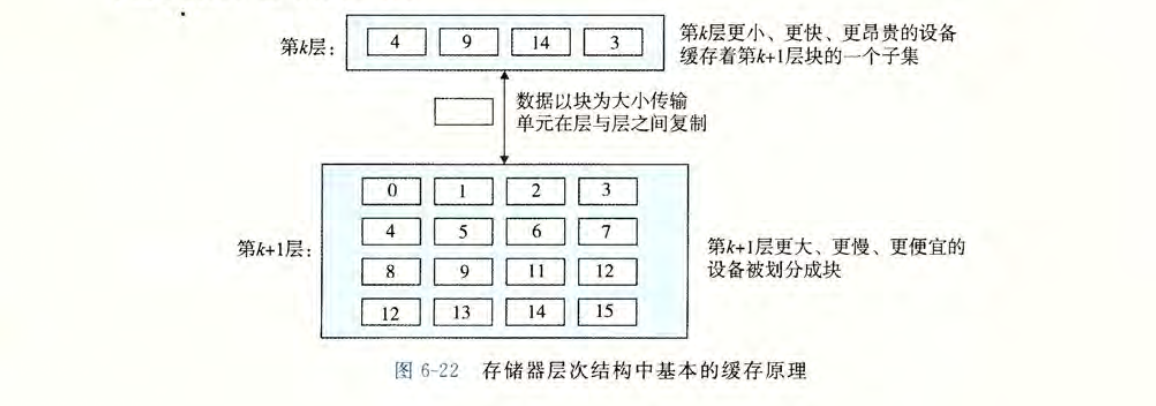
数据总是以块block为单位,在层与层之间来回复制。
说回高速缓存,按照摩尔定律,CPU 的访问速度每 18 个月便会翻一翻,相当于每年增长 60%。内存的访问速度虽然不断增长,却远没有那么快,每年只增长 7% 左右。这样就导致 CPU 性能和内存访问的差距不断拉大。为了弥补两者之间差异,现代 CPU 引入了高速缓存。
CPU 的读(load)实质上就是从缓存中读取数据到寄存器(register)里,在多级缓存的架构中,如果缓存中找不到数据(Cache miss),就会层层读取二级缓存三级缓存,一旦所有的缓存里都找不到对应的数据,就要去内存里寻址了。寻址到的数据首先放到寄存器里,其副本会驻留到 CPU 的缓存中。
CPU 的写(store)也是针对缓存作写入。并不会直接和内存打交道,而是通过某种机制实现数据从缓存到内存的写回(write back)。
缓存到底如何与 CPU 和主存数据交换的?CPU 如何从缓存中读写数据的?缓存中没有读的数据,或者缓存写满了怎么办?我们先从 CPU 如何读取数据说起。
缓存读取
CPU 发起一个读取请求后,返回的结果会有如下几种情况:
- 缓存命中 (cache hit) 要读取的数据刚好在缓存中,叫做缓存命中。
- 缓存不命中 (cache miss)
发送缓存不命中,缓存就得执行一直放置策略(placement policy),比如 LRU。来决定从主存中取出的数据放到哪里。
- 强制性不命中(compulsory miss)/冷不命中(cold miss):缓存中没有要读取的数据,需要从主存读取数据,并将数据放入缓存。
- 冲突不命中(conflict miss):缓存中有要读的数据,在采取放置策略时,从主存中取数据放到缓存时发生了冲突,这叫做冲突不命中。
高速缓存存储器组织结构
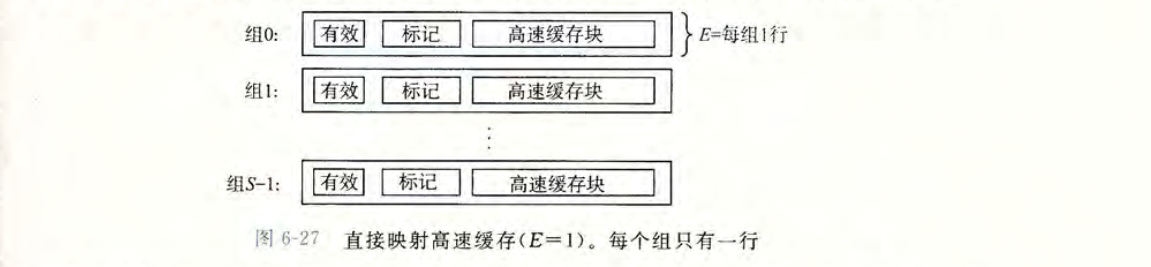
整个 Cache 被划分为 1 个或多个组 (Set),$S$ 表示组的个数。每个组包含 1 个或多个缓存行(Cache line),$E$ 表示一个组中缓存行的行数。每个缓存行由三部分组成:有效位(valid),标记位(tag),数据块(cache block)。
- 有效位:该位等于 1,表示这个行数据有效。
- 标记位:唯一的标识了存储在高速缓存中的块,标识目标数据是否存在当前的缓存行中。
- 数据块:一部分内存数据的副本。

Cache 的结构可以由元组$(S,E,B,m)$表示。不包括有效位和标记位。Cache 的大小为 $C=S \times E \times B$.
接下来看看 Cache 是如何工作的,当 CPU 执行数据加载指令,从内存地址 A 读取数据时,根据存储器层次原理,如果 Cache 中保存着目标数据的副本,那么就立即将数据返回给 CPU。那么 Cache 如何知道自己保存了目标数据的副本呢?
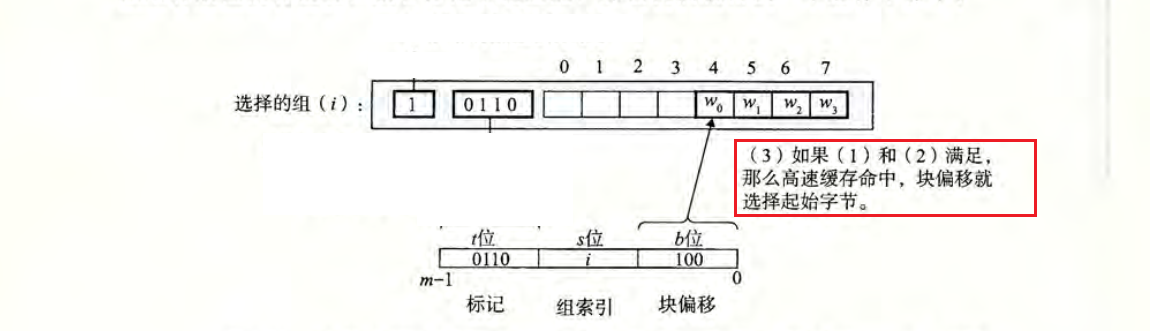
假设目标地址的数据长度为$m$位,这个地址被参数 $S$ 和 $B$ 分成了三个字段:

首先通过长度为$s$的组索引,确定目标数据保存在哪一个组 (Set) 中,其次通过长度为$t$的标记,确定在哪一行,需要注意的是此时有效位必须等于 1,最后根据长度为$b$的块偏移,来确定目标数据在数据块中的确切位置。
Q:既然读取 Cache 第一步是组选择,为什么不用高位作为组索引,而使用中间的为作为组索引? A:如果使用了高位作索引,那么一些连续的内存块就会映射到相同的高速缓存块。如图前四个块映射到第一个缓存组,第二个四个块映射到第二个组,依次类推。如果一个程序有良好的空间局部性,顺序扫描一个数组的元素,那么在任何时候,缓存中都只保存在一个块大小的数组内容。这样对缓存的使用率很低。相比而言,如果使用中间的位作为组索引,那么相邻的块总是映射到不同的组,图中的情况能够存放整个大小的数组片。
Responsive Image

直接映射高速缓存 Direct Mapped Cache
根据每个组的缓存行数 $E$ 的不同,Cache 被分为不同的类。每个组只有一行$E=1$的高速缓存被称为直接映射高速缓存(direct-mapped cache)。
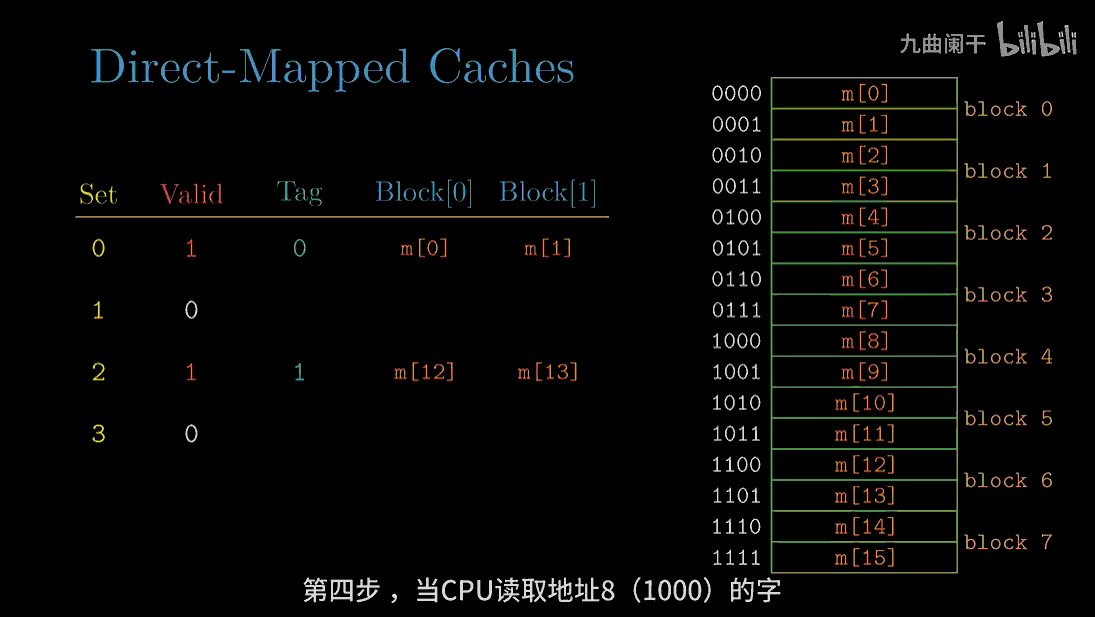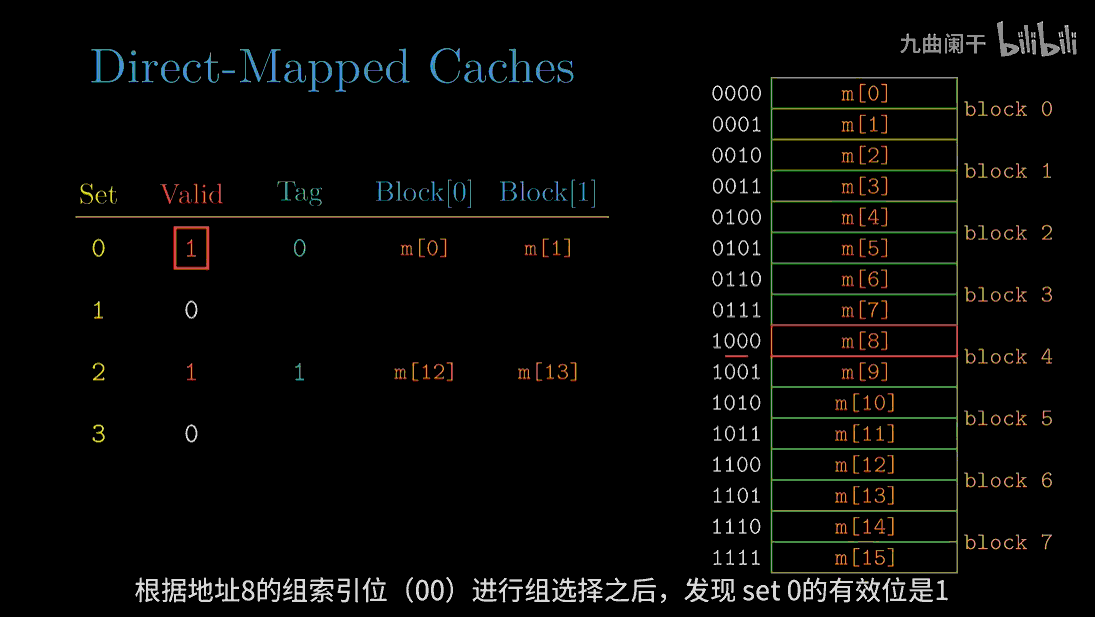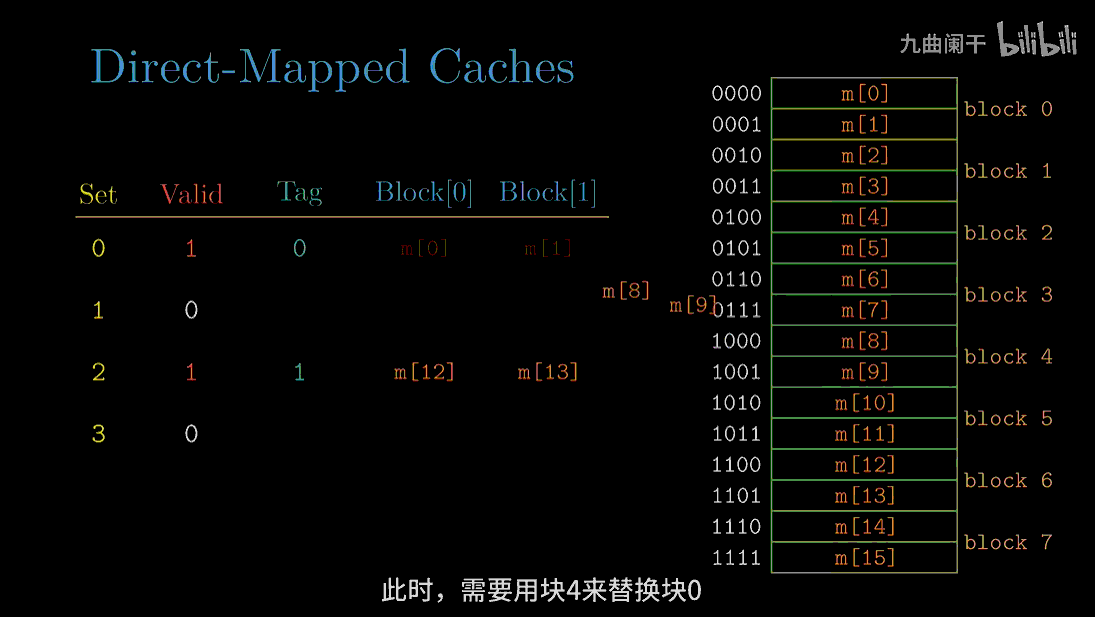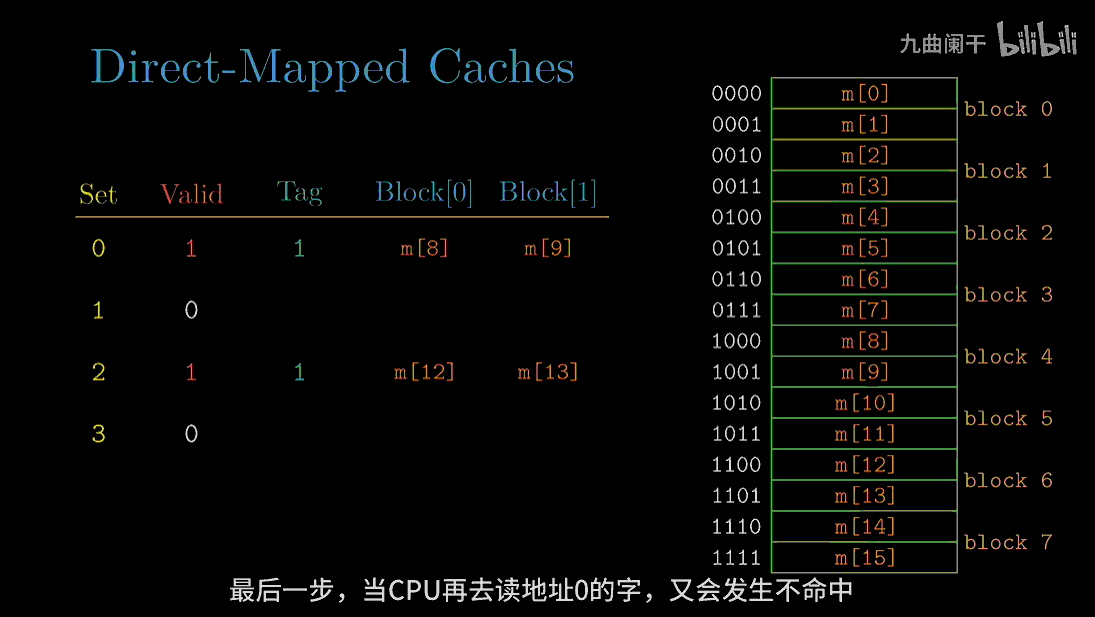
当一条加载指令指示 CPU 从主存地址 A 中读取一个字 w 时,会将该主存地址 A 发送到高速缓存中,则高速缓存会根据组选择,行匹配和字抽取三步来判断地址 A 是否命中。
组选择(set selection):根据组索引值来确定属于哪一个组,如图中索引长度为 5 位,可以检索 32 个组 ($2^5=32$)。当$s=0$时,此时组选择的结果为set 0,当$s=1$时,此时组选择的结果为set 1。

行匹配 (line match):首先看缓存行的有效位,此时有效位为 1,表示当前数据有效。然后对比缓存行的标记0110与地址中的标记0110是否相等,如果相等,则表示目标数据在当前的缓存行中(缓存命中)。如果不一致或者有效位为 0,则表示目标数据不在当前的缓存行中(缓存不命中)。如果命中,就可以进行下一步字抽取。

字抽取 (word extraction):根据偏移量$b$确定目标数据的确切位置,通俗来说就是从数据块的什么位置开始抽取位置。如当偏移块等于100时,表示目标数据起始地址位于字节 4 处。
下面通过一个例子来解释清除这个过程。假设我们有一个直接映射高速缓存,描述为$(S,E,B,m) = (4,1,2,4)$。换句话说,高速缓存有 4 个组,每个组 1 行,每个数据块 2 个字节,地址长度为 4 位。
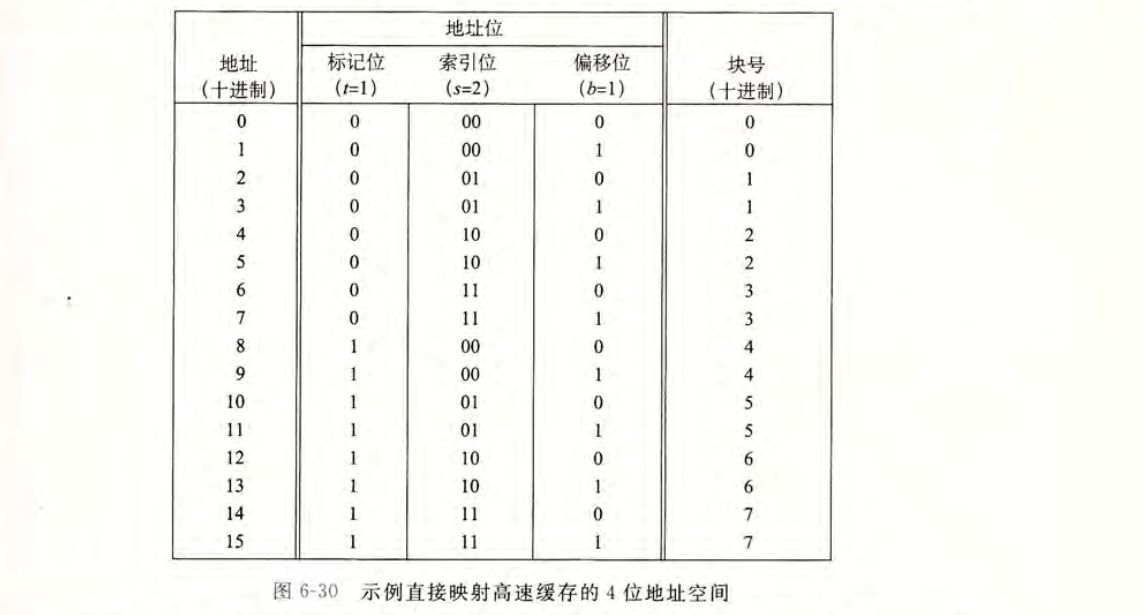
从图中可以看出,8 个内存块,但只有 4 个高速缓存组,所以会有多个块映射到同一个高速缓存组中。例如,块 0 和块 4 都会被映射到组 0。
下面我们来模拟当 CPU 执行一系列读的时候,高速缓存的执行情况,我们假设每次 CPU 读 1 个字节的字。
读地址 0(0000) 的字:
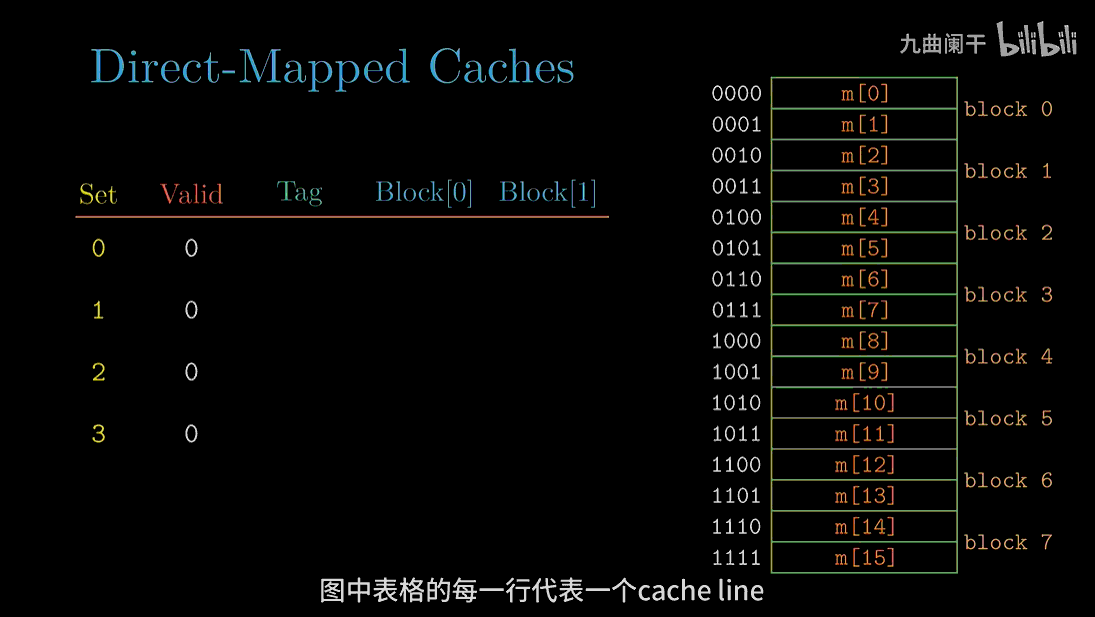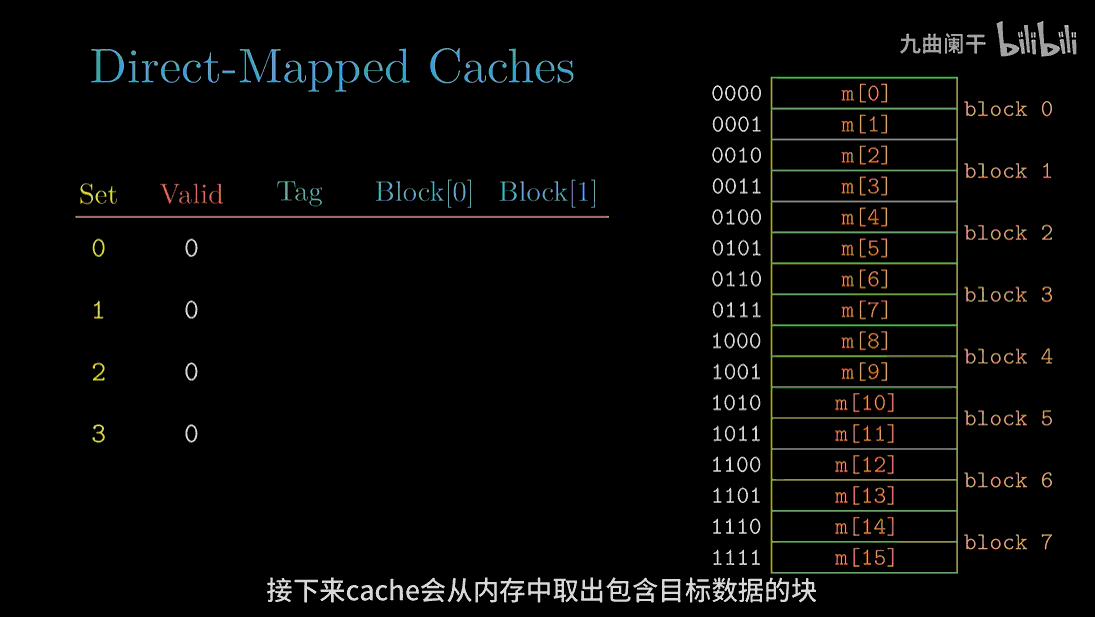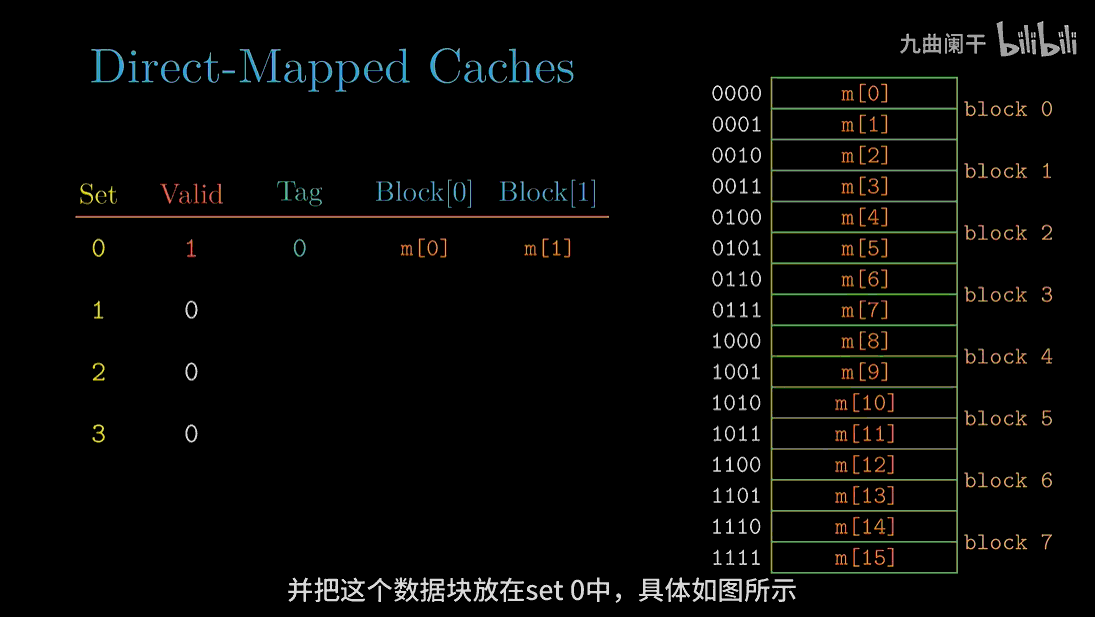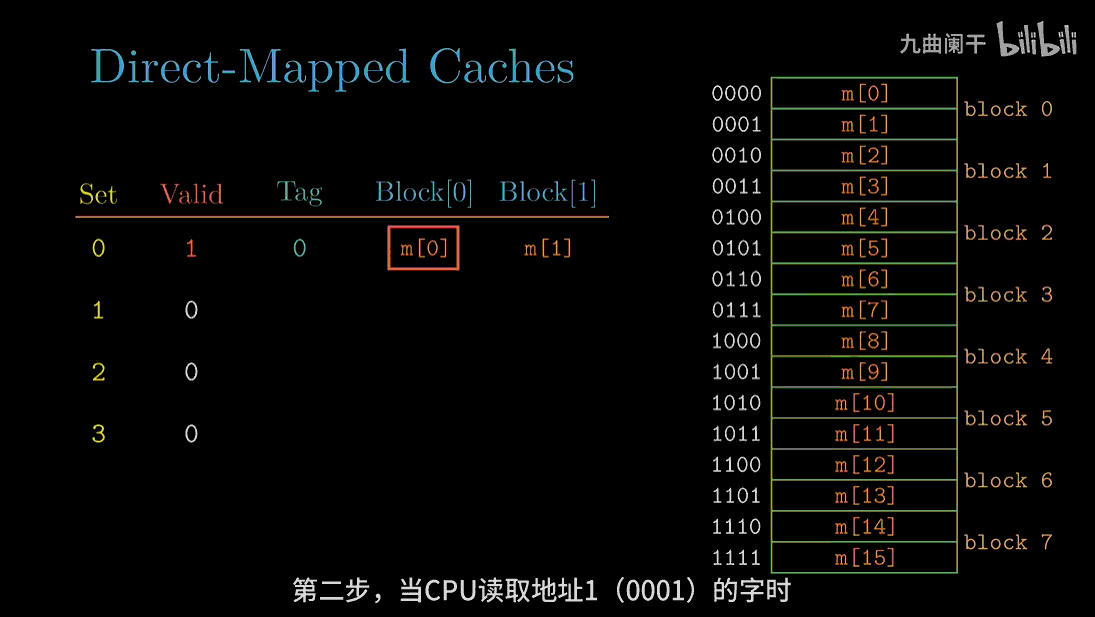
读地址 1(0001) 的字:

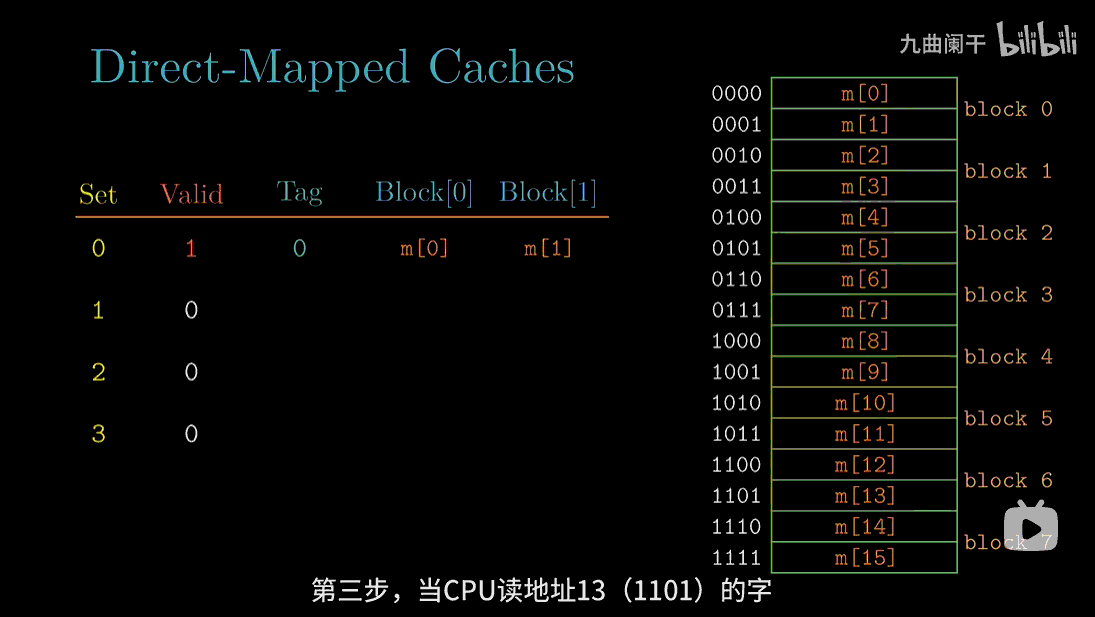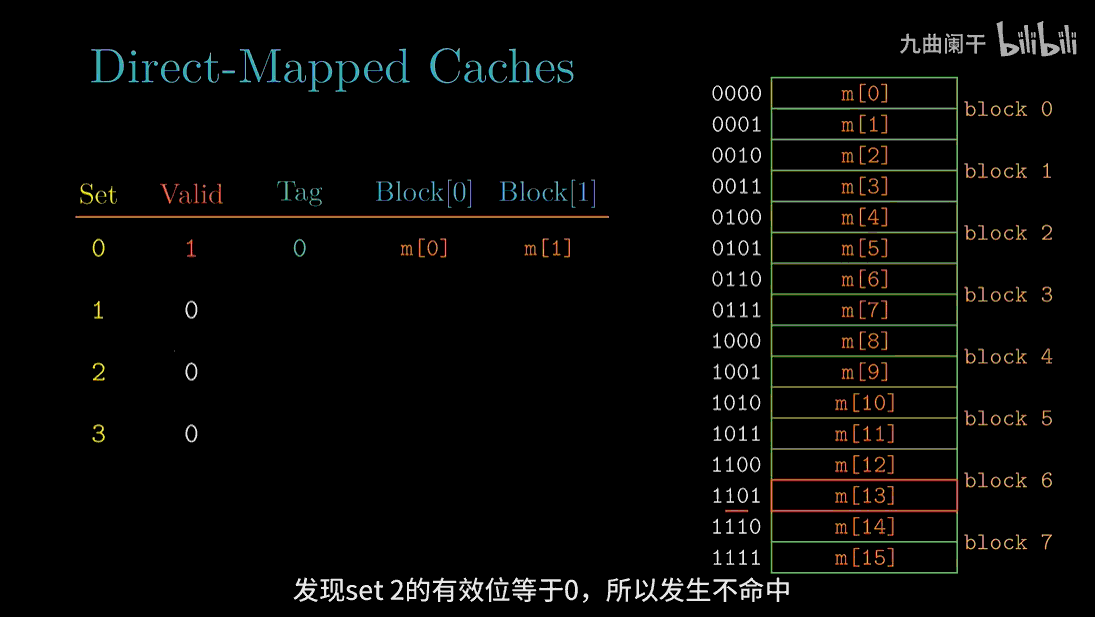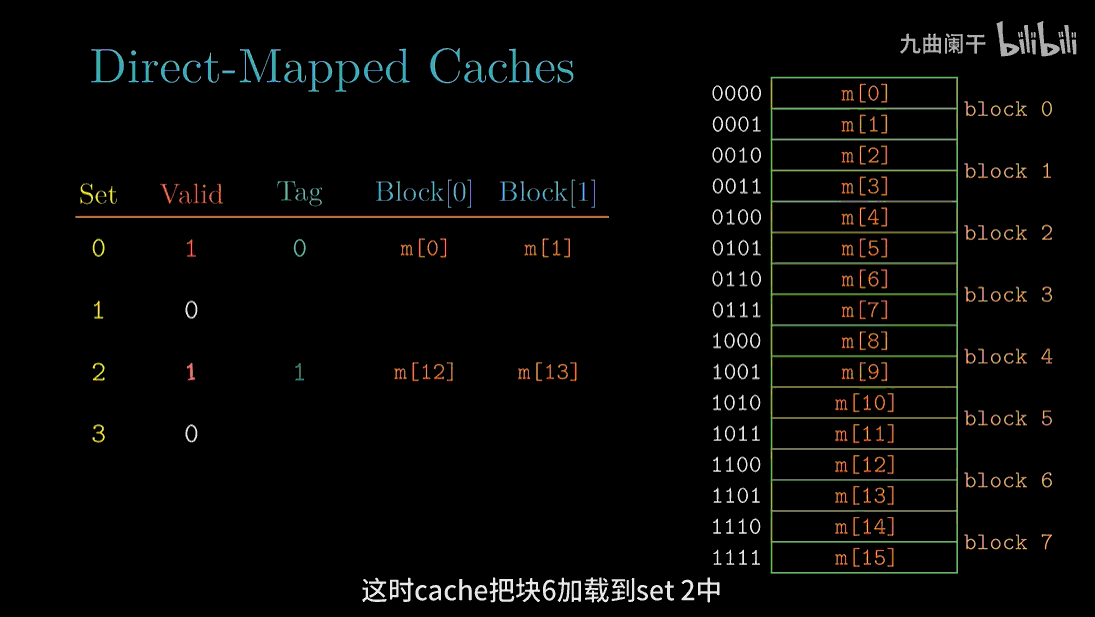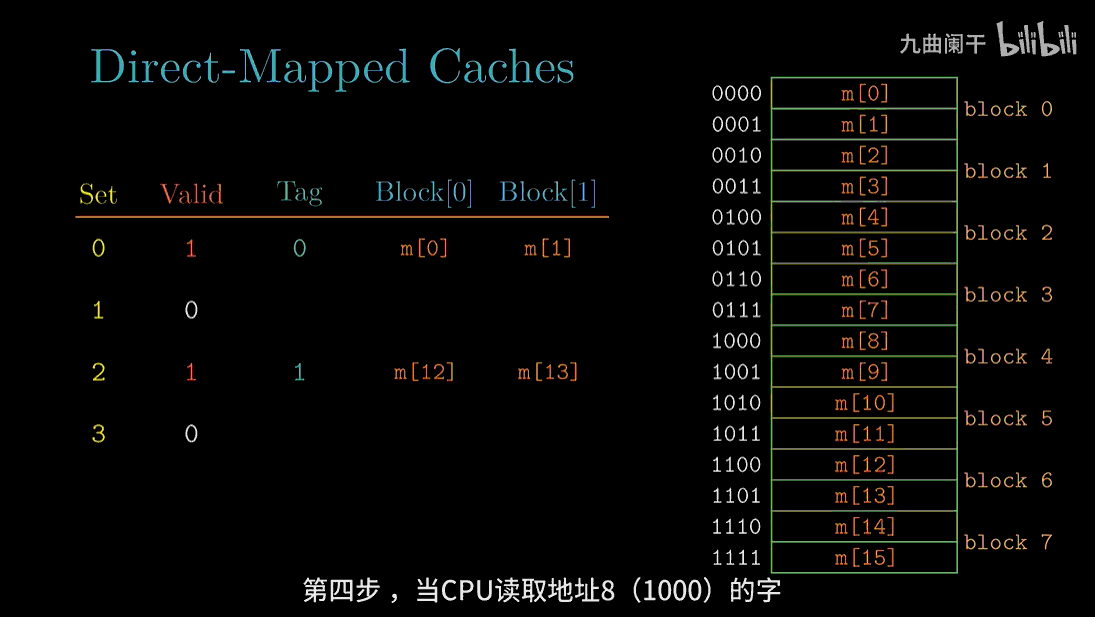
读地址 13(1101) 的字:
读地址 8(1000) 的字:
读地址 0(0000) 的字:

组相联高速缓存 Set Associative Cache
由于直接映射高速缓存的组中只有一行,所以容易发生冲突不命中。组相联高速缓存 (Set associative cache) 运行有多行缓存行。但是缓存行最大不能超过 $C/B$。
如图一个组中包含了两行缓存行,这种我们称为 2 路相联高速缓存。
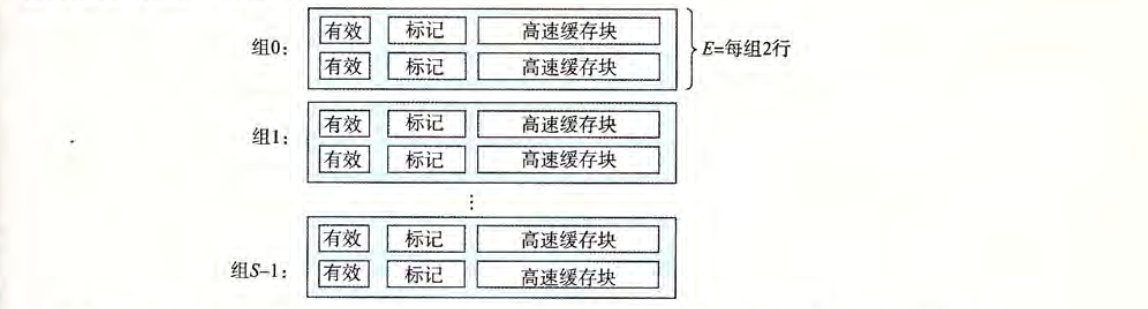
组选择:与直接映射高速缓存的组选择过程一样。
行匹配:因为一个组有多行,所以需要遍历所有行,找到一个有效位为 1,并且标记为与地址中的标记位相匹配的一行。如果找到了,表示缓存命中。
字抽取:根据偏移量$b$确定目标数据的确切位置,通俗来说就是从数据块的什么位置开始抽取位置。如当偏移块等于100时,表示目标数据起始地址位于字节 4 处。
如果不命中,那么就需要从主存中取出需要的数据块,但是将数据块放在哪一行缓存行呢?如果存在空行 ($valid=0$),那就放到空行里。如果没有空行,就得选择一个非空行来替换,同时希望 CPU 不会很快引用这个被替换的行。这里介绍几个替换策略。
最简单的方式就是随机选择一行来替换,其他复杂的方式就是利用局部性原理,使得接下来 CPU 引用替换的行概率最小。如
缓存一致性协议 MESI
为什么需要缓存一致
目前主流电脑的 CPU 都是多核心的,多核心的有点就是在不能提升 CPU 主频后,通过增加核心来提升 CPU 吞吐量。每个核心都有自己的 L1 Cache 和 L2 Cache,只是共用 L3 Cache 和主内存。每个核心操作是独立的,每个核心的 Cache 就不是同步更新的,这样就会带来缓存一致性(Cache Coherence)的问题。
举个例子,如图:
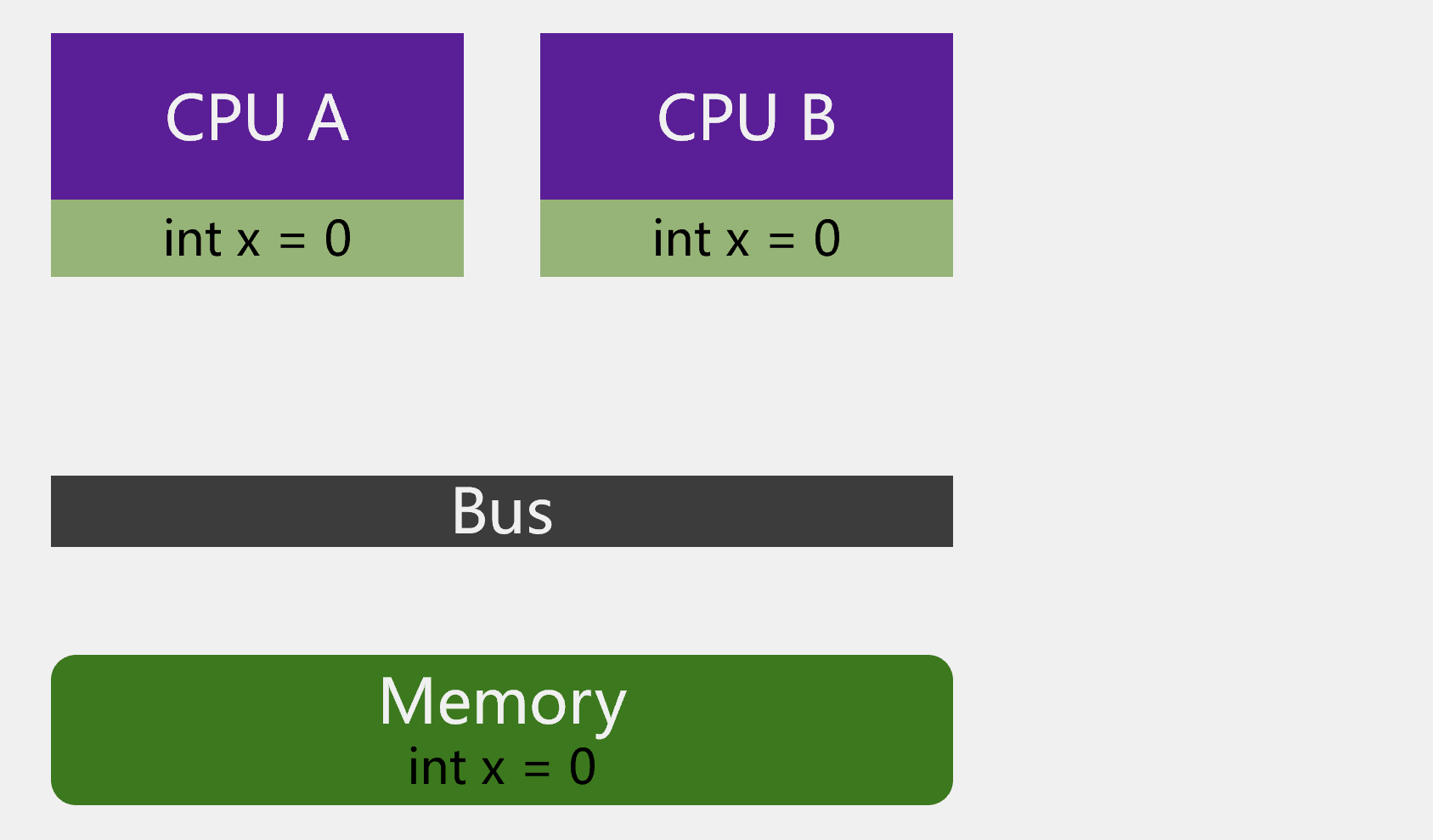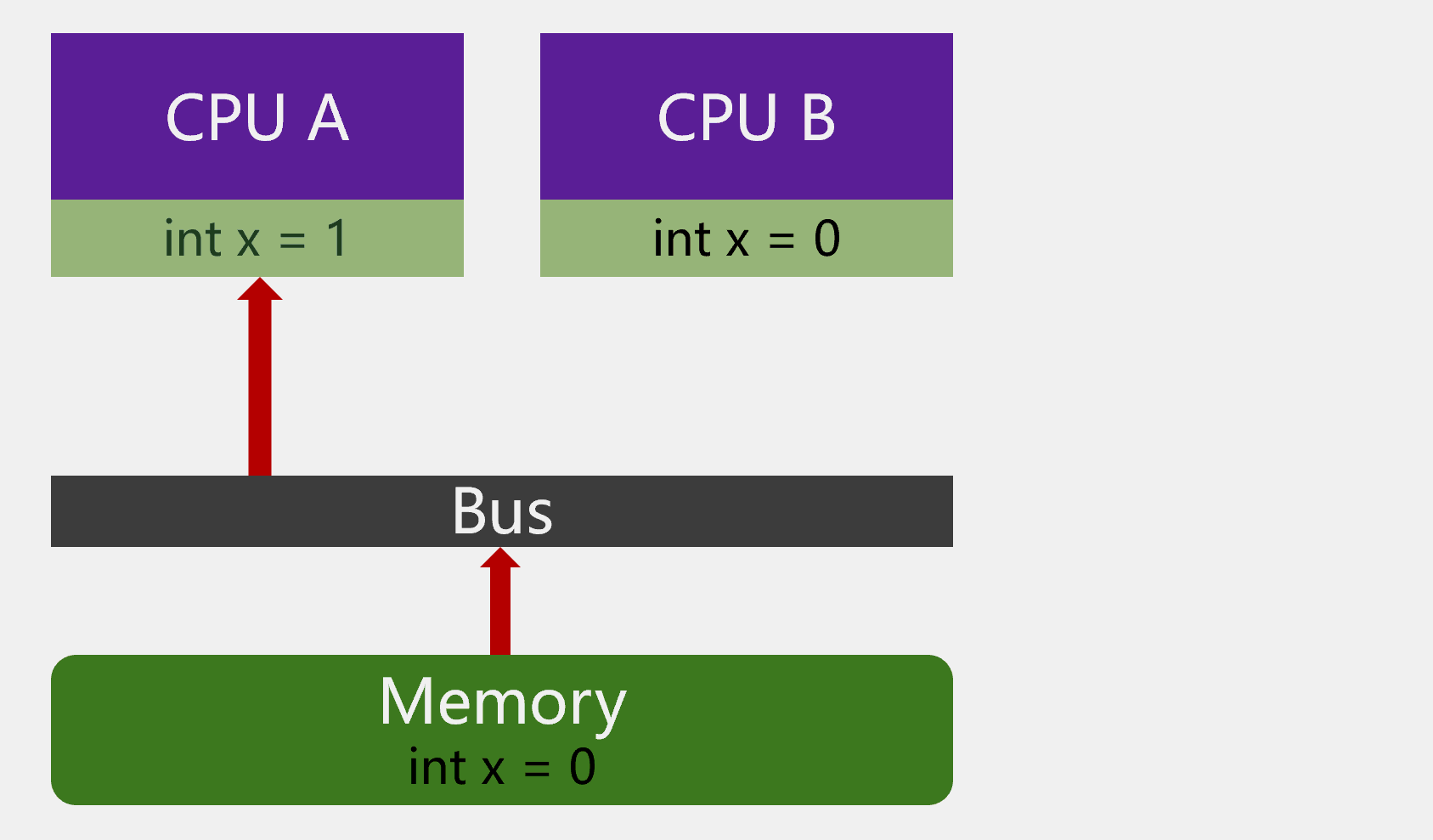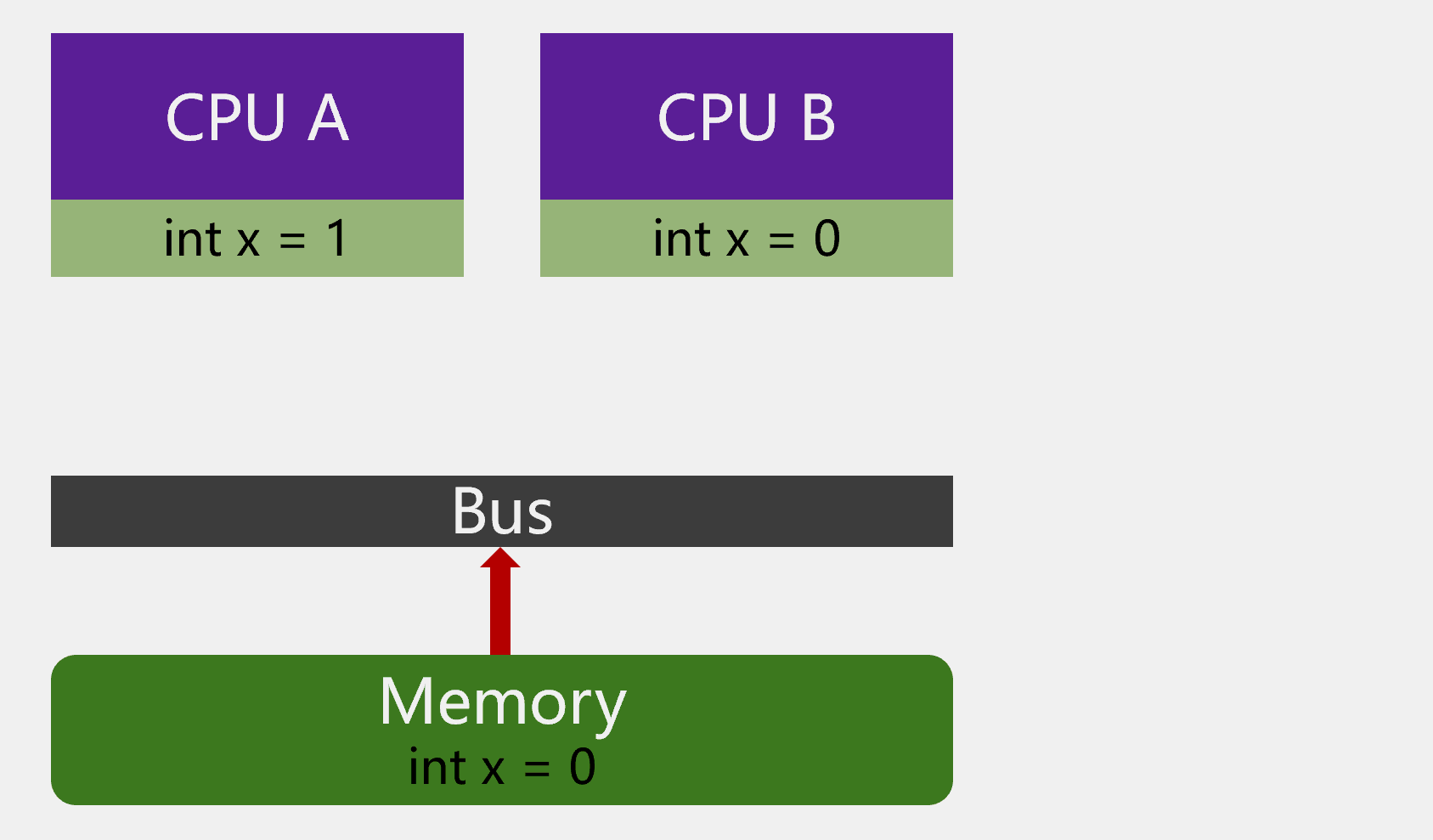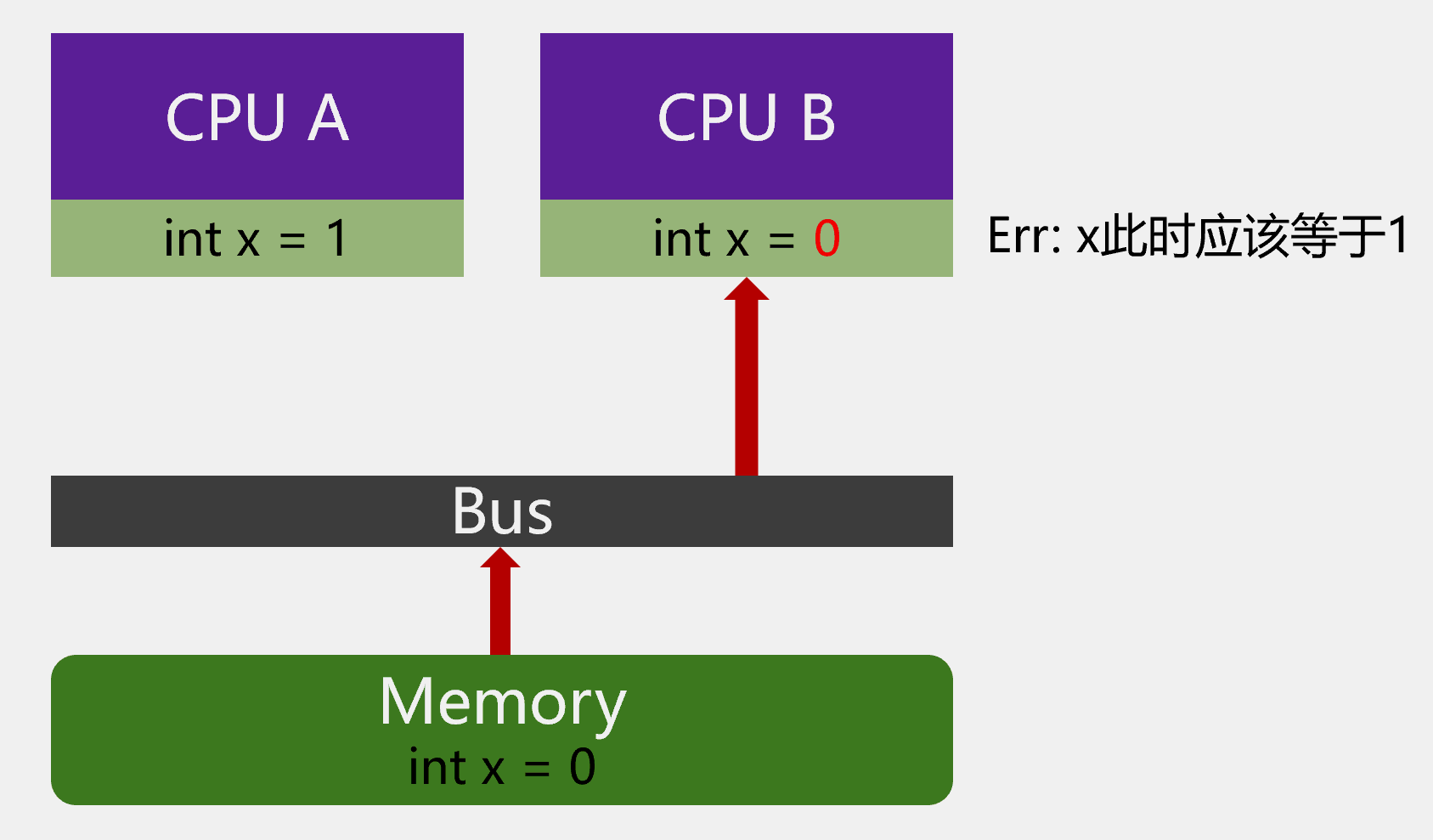
有 2 个 CPU,主内存里有个变量x=0。CPU A 中有个需要将变量x加1。CPU A 就将变量x加载到自己的缓存中,然后将变量x加1。因为此时 CPU A 还未将缓存数据写回主内存,CPU B 再读取变量x时,变量x的值依然是0。
这里的问题就是所谓的缓存一致性问题,因为 CPU A 的缓存与 CPU B 的缓存是不一致的。
如何解决缓存一致性问题
通过在总线加 LOCK 锁的方式
在锁住总线上加一个 LOCK 标识,CPU A 进行读写操作时,锁住总线,其他 CPU 此时无法进行内存读写操作,只有等解锁了才能进行操作。
该方式因为锁住了整个总线,所以效率低。
缓存一致性协议 MESI
该方式对单个缓存行的数据进行加锁,不会影响到内存其他数据的读写。
在学习 MESI 协议之前,简单了解一下总线嗅探机制(Bus Snooping)。要对自己的缓存加锁,需要通知其他 CPU,多个 CPU 核心之间的数据传播问题。最常见的一种解决方案就是总线嗅探。
这个策略,本质上就是把所有的读写请求都通过总线广播给所有的 CPU 核心,然后让各个核心去“嗅探”这些请求,再根据本地的情况进行响应。MESI 就是基于总线嗅探机制的缓存一致性协议。
MESI 协议的由来是对 Cache Line 的四个不同的标记,分别是:
状态 | 状态 | 描述 | 监听任务 |
|---|---|---|---|
| Modified | 已修改 | 该 Cache Line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中 | Cache Line 必须时刻监听所有试图读该 Cache Line 相对于主存的操作,这种操作必须在缓存将该 Cache Line 写回主存并将状态改为 S 状态之前,被延迟执行 |
| Exclusive | 独享,互斥 | 该 Cache Line 有效,数据和内存中的数据一直,数据只存在于本 Cache | Cache Line 必须监听其他缓存读主存中该 Cache Line 的操作,一旦有这种操作,该 Cache Line 需要改为 S 状态 |
| Shared | 共享的 | 该 Cache Line 有效,数据和内存中的数据一直,数据存在于很多个 Cache 中 | Cache Line 必须监听其他 Cache Line 使该 Cache Line 无效或者独享该 Cache Line 的请求,并将 Cache Line 改为 I 状态 |
| Invalid | 无效的 | 该 Cache Line 无效 | 无 |
整个 MESI 的状态,可以用一个有限状态机来表示它的状态流转。需要注意的是,对于不同状态触发的事件操作,可能来自于当前 CPU 核心,也可能来自总线里其他 CPU 核心广播出来的信号。我把各个状态之间的流转用表格总结了一下:
当前状态 | 事件 | 行为 | 下个状态 |
|---|---|---|---|
| M | Local Read | 从 Cache 中读,状态不变 | M |
| M | Local Write | 修改 cache 数据,状态不变 | M |
| M | Remote Read | 这行数据被写到内存中,使其他核能使用到最新数据,状态变为 S | S |
| M | Remote Write | 这行数据被写入内存中,其他核可以获取到最新数据,由于其他 CPU 修改该条数据,则本地 Cache 变为 I | I |
当前状态 | 事件 | 行为 | 下个状态 |
|---|---|---|---|
| E | Local Read | 从 Cache 中读,状态不变 | E |
| E | Local Write | 修改数据,状态改为 M | M |
| E | Remote Read | 数据和其他 CPU 共享,变为 S | S |
| E | Remote Write | 数据被修改,本地缓存失效,变为 I | I |
当前状态 | 事件 | 行为 | 下个状态 |
|---|---|---|---|
| S | Local Read | 从 Cache 中读,状态不变 | S |
| S | Local Write | 修改数据,状态改为 M,其他 CPU 的 Cache Line 状态改为 I | M |
| S | Remote Read | 数据和其他 CPU 共享,状态不变 | S |
| S | Remote Write | 数据被修改,本地缓存失效,变为 I | I |
当前状态 | 事件 | 行为 | 下个状态 |
|---|---|---|---|
| I | Local Read | 1. 如果其他 CPU 没有这份数据,直接从内存中加载数据,状态变为 E; 2. 如果其他 CPU 有这个数据,且 Cache Line 状态为 M,则先把 Cache Line 中的内容写回到主存。本地 Cache 再从内存中读取数据,这时两个 Cache Line 的状态都变为 S; 3. 如果其他 Cache Line 有这份数据,并且状态为 S 或者 E,则本地 Cache Line 从主存读取数据,并将这些 Cache Line 状态改为 S | E 或者 S |
| I | Local Write | 1. 先从内存中读取数据,如果其他 Cache Line 中有这份数据,且状态为 M,则现将数据更新到主存再读取,将 Cache Line 状态改为 M; 2. 如果其他 Cache Line 有这份数据,且状态为 E 或者 S,则其他 Cache Line 状态改为 I | M |
| I | Remote Read | 数据和其他 CPU 共享,状态不变 | S |
| I | Remote Write | 数据被修改,本地缓存失效,变为 I | I |
内存
计算机有五大组成部分,分别是:运算器、控制器、存储器、输入设备和输出设备。而内存就是其中的存储器。我们的数据和指令都需要先放到内存中,然后再被 CPU 执行。
操作系统中程序并不能直接访问物理内存,我们的内存需要被分成固定大小的页(Page),然后再通过虚拟内存地址(Virtual Address)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置。而我们的程序看到的内存地址,都是虚拟内存地址。那么如何进行转换的呢?
简单页表
最简单的方式,就是建立一张虚拟内存到物理内存的映射表,在计算机里叫做页表(Page Table)。页表这个地址转换的办法,会把一个内存地址分成页号(Directory)和偏移量(Offset)两个部分,是不是似曾相识,因为在前面的高速缓存里,缓存的结构也是这样的。
以一个 32 位地址举例,高 20 位是虚拟页号,可以从虚拟页表中找到物理页号的信息,低 12 位是偏移量,可以准确获得物理地址。
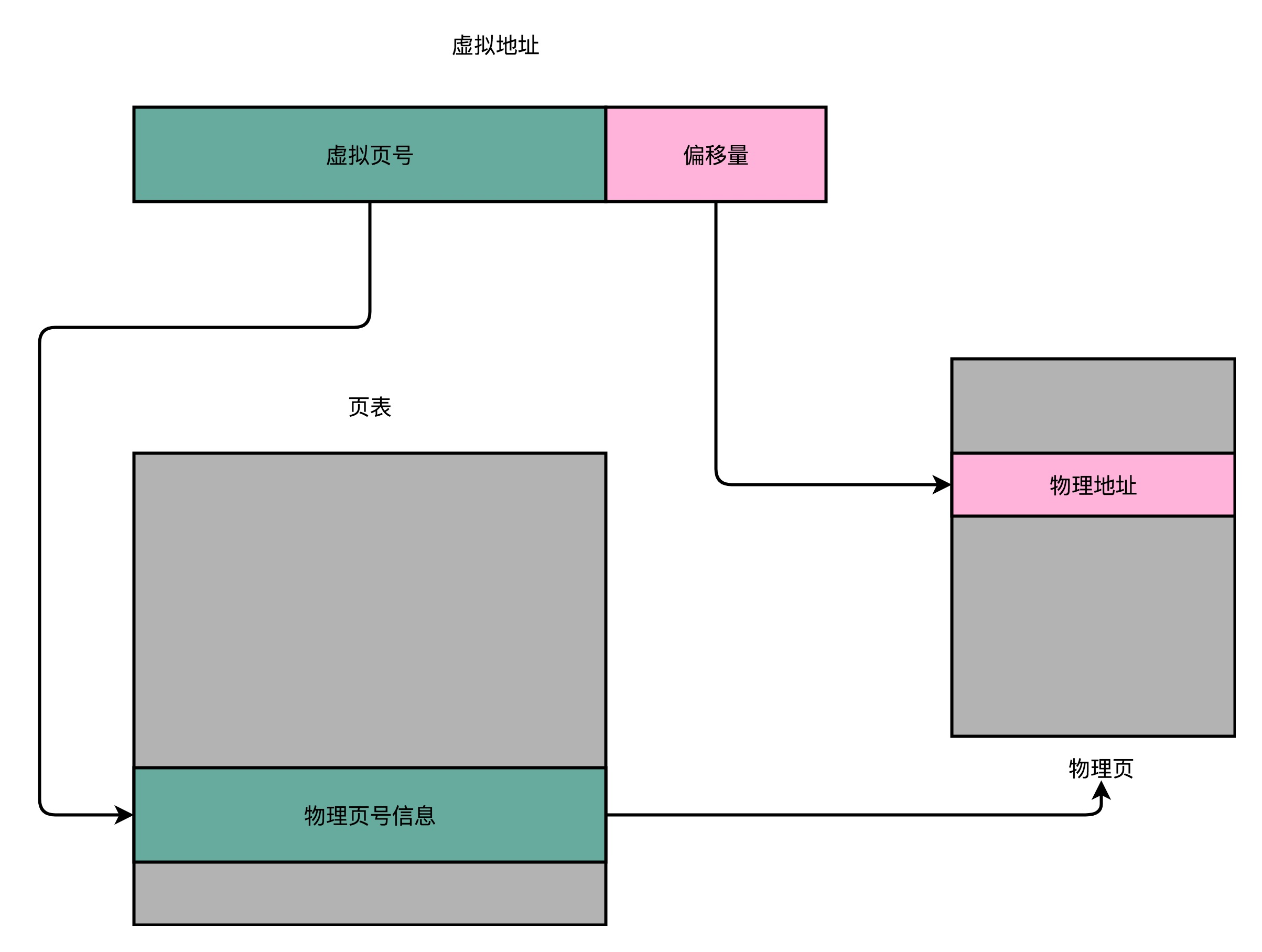
总结一下,对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量的组合;
- 从页表里面,查询出虚拟页号,对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
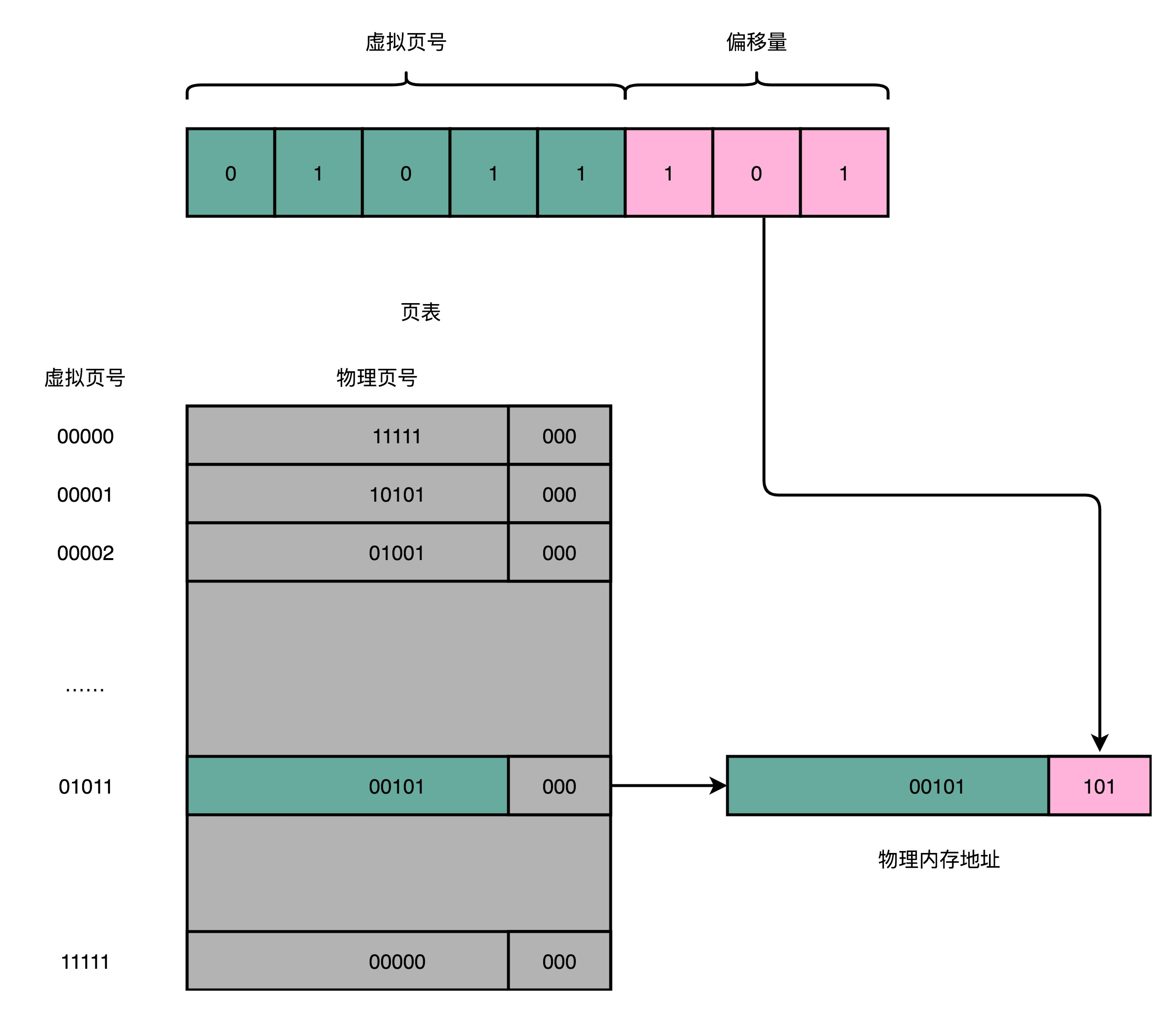
但是这样的页表有个问题,它需要记录$2^{20}$个物理页表,这个存储关系,就好比一个 $2^{20}$大小的数组。一个页号是完整的 32 位的 4 字节(Byte),这样一个页表就需要 4MB 的空间。并且每个进程都会有这样一个页表,现代电脑正常都有成百上千个进程,如果用这样的页表肯定行不通的。
多级页表
所以,在一个实际的程序进程里面,虚拟内存占用的地址空间,通常是两段连续的空间。而不是完全散落的随机的内存地址。而多级页表,就特别适合这样的内存地址分布。
TLB
内存保护 - 可执行空间保护
内存保护 - 地址空间布局随机化
Address Space Layout Randomization
总线:计算机内部的高速公路
计算机由控制器、运算器、存储器、输入设备以及输出设备五大部分组成。CPU 所代表的控制器和运算器,要和存储器,也就是我们的主内存,以及输入和输出设备进行通信。那么计算机是用什么样的方式来完成,CPU 和内存、以及外部输入输出设备的通信呢?答案就是通过总线来通信。
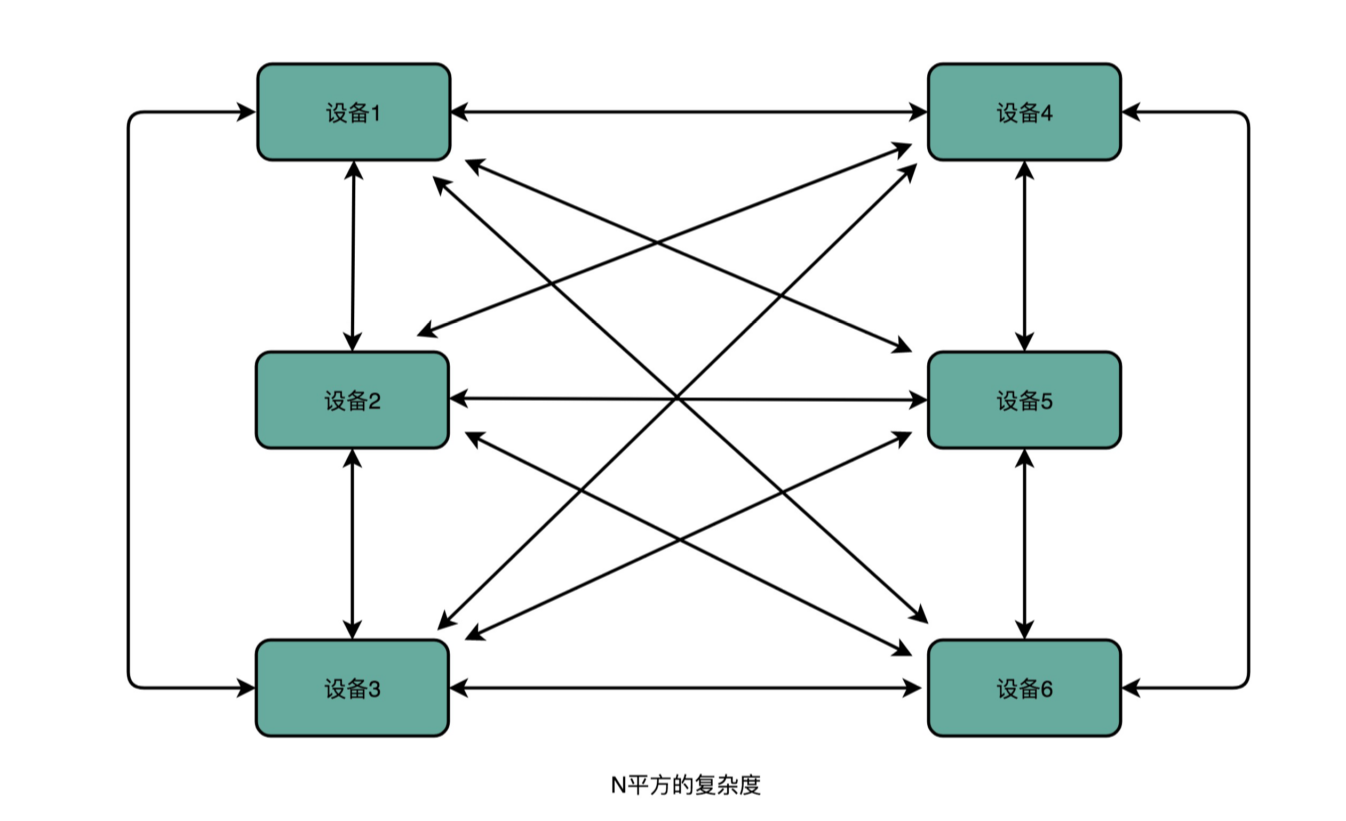
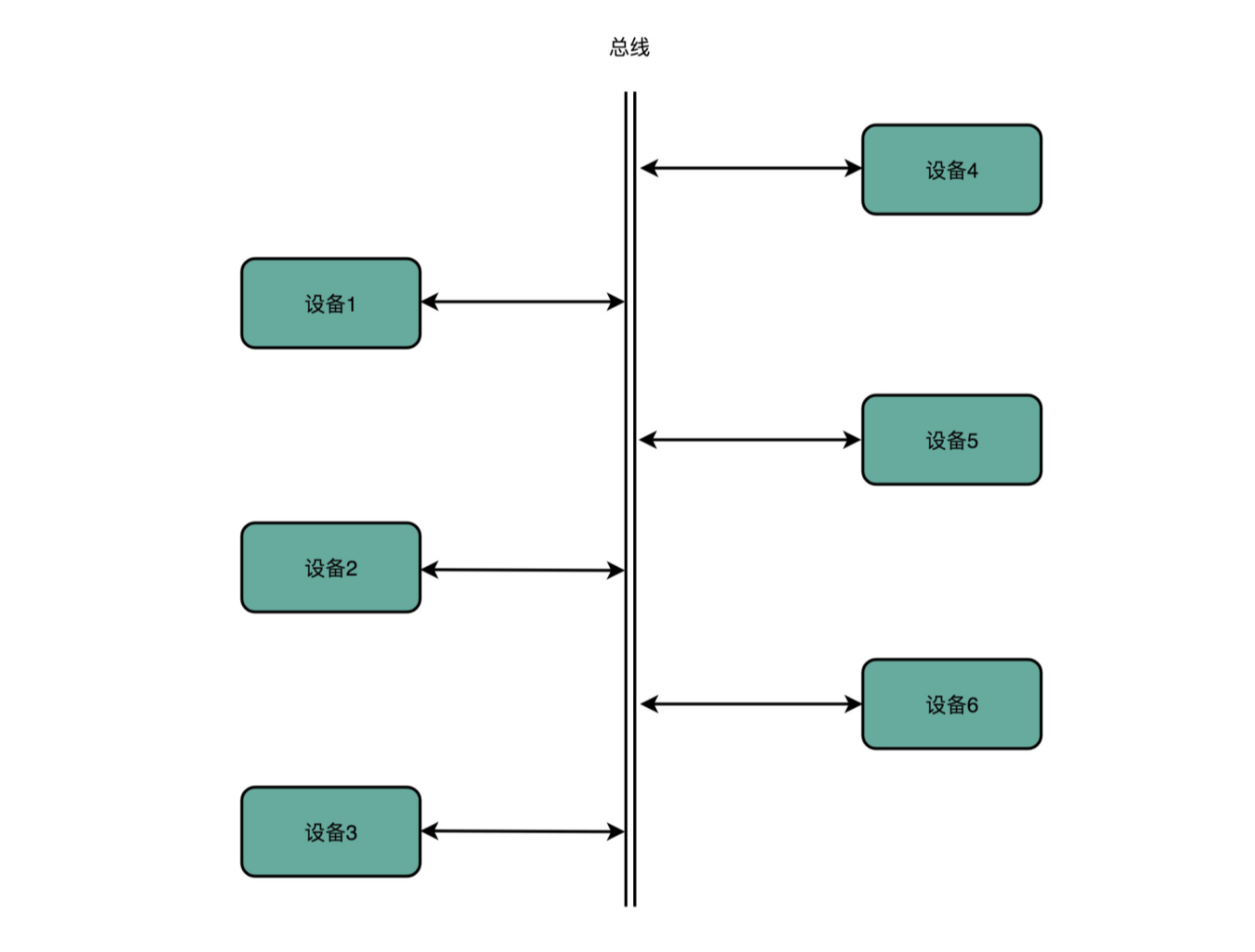
计算机里有不同的硬件设备,如果设备与设备之间都单独连接,那么就需要 N*N 的连线。那么怎么降低复杂度呢?与其让各个设备之间互相单独通信,不如我们去设计一个公用的线路。CPU 想要和什么设备通信,通信的指令是什么,对应的数据是什么,都发送到这个线路上;设备要向 CPU 发送什么信息呢,也发送到这个线路上。这个线路就好像一个高速公路,各个设备和其他设备之间,不需要单独建公路,只建一条小路通向这条高速公路就好了。
三种线路和多总线架构
首先,CPU 和内存以及高速缓存通信的总线,这里面通常有两种总线。这种方式,我们称之为双独立总线(Dual Independent Bus,缩写为 DIB)。CPU 里,有一个快速的本地总线(Local Bus),以及一个速度相对较慢的前端总线(Front-side Bus)。
现代的 CPU 里,通常有专门的高速缓存芯片。这里的高速本地总线,就是用来和高速缓存通信的。而前端总线,则是用来和主内存以及输入输出设备通信的。有时候,我们会把本地总线也叫作后端总线(Back-sideBus),和前面的前端总线对应起来。
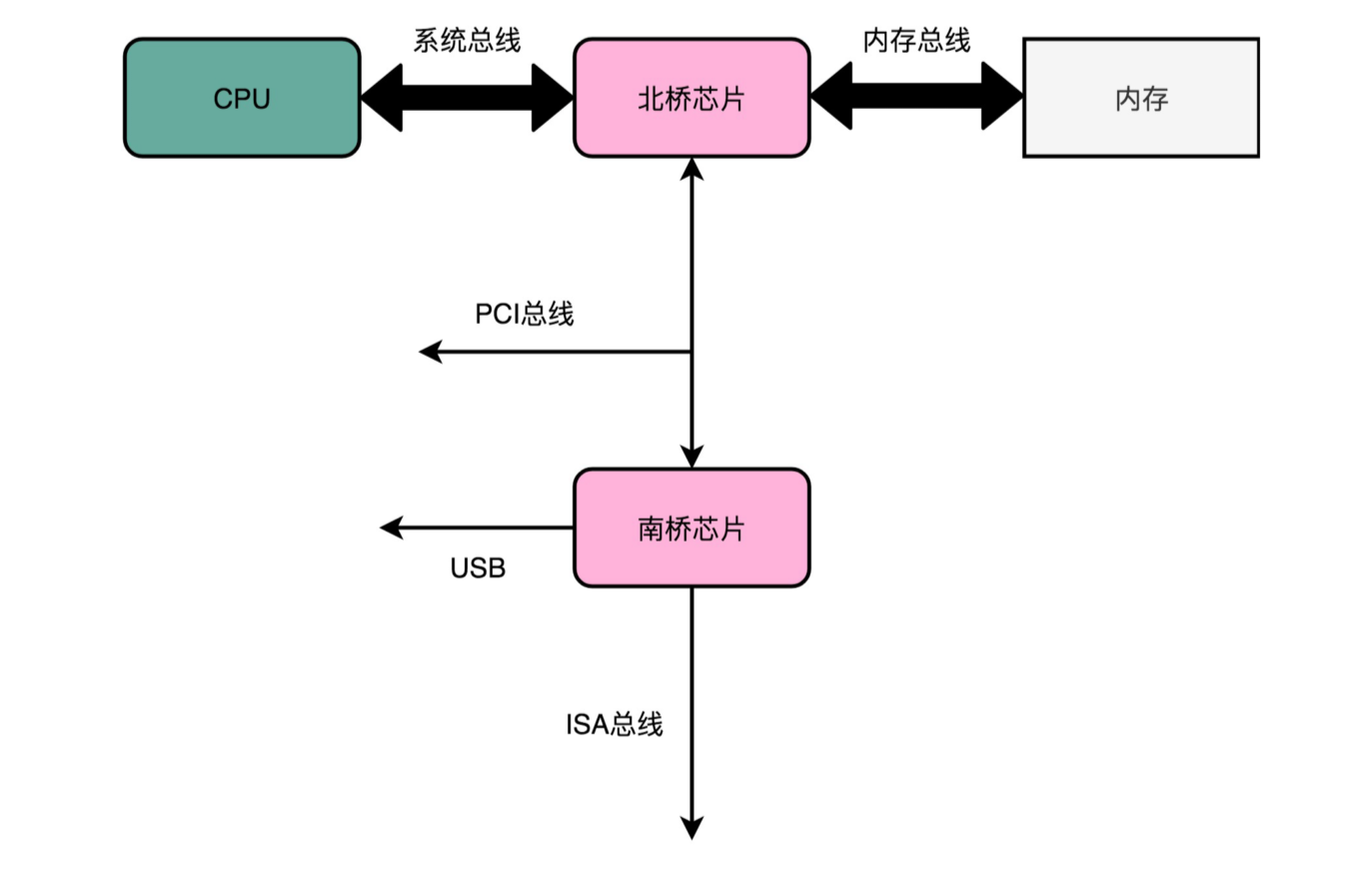
除了前端总线呢,我们常常还会听到 PCI 总线、I/O 总线或者系统总线(System Bus)。看到这么多总线的名字,你是不是已经有点晕了。这些名词确实容易混为一谈。其实各种总线的命名一直都很混乱,我们不如直接来看一看 CPU 的硬件架构图。对照图来看,一切问题就都清楚了。

CPU 里面的北桥芯片,把我们上面说的前端总线,一分为二,变成了三个总线。我们的前端总线,其实就是系统总线。CPU 里面的内存接口,直接和系统总线通信,然后系统总线再接入一个 I/O 桥接器(I/OBridge)。这个 I/O 桥接器,一边接入了我们的内存总线,使得我们的 CPU 和内存通信;另一边呢,又接入了一个 I/O 总线,用来连接 I/O 设备。
事实上,真实的计算机里,这个总线层面拆分得更细。根据不同的设备,还会分成独立的 PCI 总线、ISA 总线等等。
在物理层面,其实我们完全可以把总线看作一组“电线”。不过呢,这些电线之间也是有分工的,我们通常有三类线路。
- 数据线(Data Bus),用来传输实际的数据信息,也就是实际上了公交车的“人”。
- 地址线(Address Bus),用来确定到底把数据传输到哪里去,是内存的某个位置,还是某一个 I/O 设备。这个其实就相当于拿了个纸条,写下了上面的人要下车的站点。
- 控制线(ControlBus),用来控制对于总线的访问。虽然我们把总线比喻成了一辆公交车。那么有人想要做公交车的时候,需要告诉公交车司机,这个就是我们的控制信号。
尽管总线减少了设备之间的耦合,也降低了系统设计的复杂度,但同时也带来了一个新问题,那就是总线不能同时给多个设备提供通信功能。
我们的总线是很多个设备公用的,那多个设备都想要用总线,我们就需要有一个机制,去决定这种情况下,到底把总线给哪一个设备用。这个机制,就叫作总线裁决(Bus Arbitraction)
硬盘
DMA
过去几年,计算机产业一直在为提升 I/O 设备的速度而努力,从机械硬盘 HDD 到固态硬盘 SSD,从 SATA 协议到 PCIE 协议,虽然速度都几十上百倍的增加,但是仍然不够快。因为相比于 CPU 基本都是 2GHz 的频率(每秒会有 20 亿次的操作),SSD 硬盘的 IOPS 的 2 万次操作就显得微不足道。
如果我们对于 I/O 的操作,都是由 CPU 发出对应的指令,然后等待 I/O 设备完成操作之后返回,那 CPU 有大量的时间其实都是在等待 I/O 设备完成操作。特别是当传输的数据量比较大的时候,比如进行大文件复制,如果所有数据都要经过 CPU,实在是有点儿太浪费时间了。
因此,计算机工程师们,就发明了DMA 技术,也就是直接内存访问(Direct Memory Access)技术,来减少 CPU 等待的时间。
什么是 DMA
本质上,DMA 技术就是我们在主板上放一块独立的芯片。在进行内存和 I/O 设备的数据传输的时候,我们不再通过 CPU 来控制数据传输,而直接通过 DMA 控制器(DMA Controller,简称 DMAC)。这块芯片,我们可以认为它其实就是一个协处理器(Co-Processor)。
DMAC 最有价值的地方体现在,当我们要传输的数据特别大、速度特别快,或者传输的数据特别小、速度特别慢的时候。
比如说,我们用千兆网卡或者硬盘传输大量数据的时候,如果都用 CPU 来搬运的话,肯定忙不过来,所以可以选择 DMAC。而当数据传输很慢的时候,DMAC 可以等数据到齐了,再向 CPU 发起中断,让 CPU 去处理,而不是让 CPU 在那里忙等待。

- 首先,CPU 还是作为一个主设备,向 DMAC 设备发起请求。这个请求,其实就是在 DMAC 里面修改配置寄存器。
- CPU 修改 DMAC 的配置的时候,会告诉 DMAC 这样几个信息:
- 源地址的初始值:数据要从哪里传输过来。如果我们要从内存里面写入数据到硬盘上,那么就是要读取的数据在内存里面的地址
- 传输时候的地址增减方式:数据是从大的地址向小的地址传输,还是从小的地址往大的地址传输
- 传输的数据长度:也就是我们一共要传输多少数据
- 设置完这些信息之后,DMAC 就会变成一个空闲的状态(Idle)。
- 如果我们要从硬盘上往内存里面加载数据,这个时候,硬盘就会向 DMAC 发起一个数据传输请求。这个请求并不是通过总线,而是通过一个额外的连线。
- 然后,我们的 DMAC 需要再通过一个额外的连线响应这个申请。
- DMAC 这个芯片,就向硬盘的接口发起要总线读的传输请求。数据就从硬盘里面,读到了 DMAC 的控制器里面。
- DMAC 再向我们的内存发起总线写的数据传输请求,把数据写入到内存里面。
- DMAC 会反复进行上面第 6、7 步的操作,直到 DMAC 的寄存器里面设置的数据长度传输完成。
- 数据传输完成之后,DMAC 重新回到第 3 步的空闲状态。
所以,整个数据传输的过程中,我们不是通过 CPU 来搬运数据,而是由 DMAC 这个芯片来搬运数据。但是 CPU 在这个过程中也是必不可少的。因为传输什么数据,从哪里传输到哪里,其实还是由 CPU 来设置的。这也是为什么,DMAC 被叫作 协处理器。